쿠버네티스의 개념
쿠버네티스란 무엇인가?
쿠버네티스는 컨테이너화된 워크로드와 서비스를 관리하기 위한 이식성이 있고, 확장가능한 오픈소스 플랫폼이다. 쿠버네티스는 선언적 구성과 자동화를 모두 용이하게 해준다. 쿠버네티스는 크고, 빠르게 성장하는 생태계를 가지고 있다. 쿠버네티스 서비스, 기술 지원 및 도구는 어디서나 쉽게 이용할 수 있다. 쿠버네티스란 명칭은 키잡이(helmsman)나 파일럿을 뜻하는 그리스어에서 유래했다. K8s라는 표기는 "K"와 "s"와 그 사이에 있는 8글자를 나타내는 약식 표기이다. 구글이 2014년에 쿠버네티스 프로젝트를 오픈소스화했다. 쿠버네티스는 프로덕션 워크로드를 대규모로 운영하는 15년 이상의 구글 경험과 커뮤니티의 최고의 아이디어와 적용 사례가 결합되어 있다.
쿠버네티스는 다음을 제공한다.
1. 서비스 디스커버리와 로드 밸런싱
쿠버네티스는 DNS 이름을 사용하거나 자체 IP 주소를 사용하여 컨테이너를 노출할 수 있다. 컨테이너에 대한 트래픽이 많으면, 쿠버네티스는 네트워크 트래픽을 로드밸런싱하고 배포하여 배포가 안정적으로 이루어질 수 있다.
2. 스토리지 오케스트레이션
쿠버네티스를 사용하면 로컬 저장소, 공용 클라우드 공급자 등과 같이 원하는 저장소 시스템을 자동으로 탑재 할 수 있다.
3. 자동화된 롤아웃과 롤백
쿠버네티스를 사용하여 배포된 컨테이너의 원하는 상태를 서술할 수 있으며 현재 상태를 원하는 상태로 설정한 속도에 따라 변경할 수 있다. 예를 들어 쿠버네티스를 자동화해서 배포용 새 컨테이너를 만들고, 기존 컨테이너를 제거하고, 모든 리소스를 새 컨테이너에 적용할 수 있다.
4. 자동화된 빈 패킹(bin packing)
컨테이너화된 작업을 실행하는데 사용할 수 있는 쿠버네티스 클러스터 노드를 제공한다. 각 컨테이너가 필요로 하는 CPU와 메모리(RAM)를 쿠버네티스에게 지시한다. 쿠버네티스는 컨테이너를 노드에 맞추어서 리소스를 가장 잘 사용할 수 있도록 해준다.
5. 자동화된 복구(self-healing)
쿠버네티스는 실패한 컨테이너를 다시 시작하고, 컨테이너를 교체하며, '사용자 정의 상태 검사'에 응답하지 않는 컨테이너를 죽이고, 서비스 준비가 끝날 때까지 그러한 과정을 클라이언트에 보여주지 않는다.
6. 시크릿과 구성 관리
쿠버네티스를 사용하면 암호, OAuth 토큰 및 SSH 키와 같은 중요한 정보를 저장하고 관리 할 수 있다. 컨테이너 이미지를 재구성하지 않고 스택 구성에 시크릿을 노출하지 않고도 시크릿 및 애플리케이션 구성을 배포 및 업데이트 할 수 있다.
https://kubernetes.io/ko/docs/concepts/overview/what-is-kubernetes/
쿠버네티스
쿠버네티스(Kubernetes, 쿠베르네테스, "K8s")는 컨테이너화된 애플리케이션의 자동 디플로이, 스케일링 등을 제공하는 관리시스템으로, 오픈 소스 기반이다. 원래 구글에 의해 설계되었고 현재 리눅스 재단에 의해 관리되고 있다. 목적은 여러 클러스터의 호스트 간에 애플리케이션 컨테이너의 배치, 스케일링, 운영을 자동화하기 위한 플랫폼을 제공하기 위함이다. 도커를 포함하여 일련의 컨테이너 도구들과 함께 동작한다.
쿠버네티스는 CPU, 메모리, 사용자 지정 메트릭스에 기반하여 애플리케이션을 디플로이하고 유지보수하고 스케일인/스케일아웃을 하는 총체적인 매커니즘을 제공하는, 프리미티브(primitive)로 불리는 빌딩 블록들의 집합을 정의한다. 쿠버네티스는 느슨하게 결합되어 있으며 각기 다른 부하를 충족하기 위해 확장이 가능하다. 이 확장성은 크게는 쿠너네티스 API에 의해 제공되며 내부 구성 요소뿐 아니라 쿠버네티스에서 실행되는 확장 기능과 컨테이너에서도 사용된다. 플랫폼은 오브젝트라는 이름의 리소스를 정의함으로써 연산 및 스토리지 자원을 통제하며 이후 이것들을 관리한다. 쿠버네티스는 프라이머리/레플리카 구조를 따른다. 쿠버네티스의 구성 요소들은 개개의 노드를 관리하는 구성 요소들과 컨트롤 플레인(control plane)의 일부인 구성 요소들로 나눌 수 있다.
https://ko.wikipedia.org/wiki/%EC%BF%A0%EB%B2%84%EB%84%A4%ED%8B%B0%EC%8A%A4
쿠버네티스 시작하기 - Kubernetes란 무엇인가?
컨테이너 오케스트레이션이 하는 일은 여러 개의 서버에 컨테이너를 배포하고 운영하면서 서비스 디스커버리Service discovery같은 기능을 이용하여 서비스 간 연결을 쉽게 해주는 것입니다. 서버마다 app01, db01, cache01 같은 이름을 지어주고 하나하나 접속하여 관리하는 것이 아니라 server1, 2, 3, 4..를 하나로 묶어 적당한 서버를 자동으로 선택해 애플리케이션을 배포하고 부하가 생기면 컨테이너를 늘리고 일부 서버에 장애가 발생하면 정상 동작 중인 서버에 다시 띄워 장애를 방지합니다.
(중략)
쿠버네티스는 컨테이너를 쉽고 빠르게 배포/확장하고 관리를 자동화해주는 오픈소스 플랫폼입니다. 몇 가지 수식어로 “운영환경에서 사용 가능한(production ready)”, “de facto(사실상 표준)”, “조타수(helmsman)”, “조종사(pilot)”, “행성 스케일(Planet Scale)”, “갓(god)” 등을 가지고 있습니다. 쿠버네티스kubernetes가 너무 길어서 오타가 많아서 흔히 케이(에이)츠k8s 또는 큐브kube라고 줄여서 부릅니다.
https://subicura.com/2019/05/19/kubernetes-basic-1.html
쿠버네티스의 필요성
쿠버네티스의 여정 돌아보기
전통적인 배포 시대: 초기 조직은 애플리케이션을 물리 서버에서 실행했었다. 한 물리 서버에서 여러 애플리케이션의 리소스 한계를 정의할 방법이 없었기에, 리소스 할당의 문제가 발생했다. 예를 들어 물리 서버 하나에서 여러 애플리케이션을 실행하면, 리소스 전부를 차지하는 애플리케이션 인스턴스가 있을 수 있고, 결과적으로는 다른 애플리케이션의 성능이 저하될 수 있었다. 이에 대한 해결책은 서로 다른 여러 물리 서버에서 각 애플리케이션을 실행하는 것이 있다. 그러나 이는 리소스가 충분히 활용되지 않는다는 점에서 확장 가능하지 않았으므로, 물리 서버를 많이 유지하기 위해서 조직에게 많은 비용이 들었다.
가상화된 배포 시대: 그 해결책으로 가상화가 도입되었다. 이는 단일 물리 서버의 CPU에서 여러 가상 시스템 (VM)을 실행할 수 있게 한다. 가상화를 사용하면 VM간에 애플리케이션을 격리하고 애플리케이션의 정보를 다른 애플리케이션에서 자유롭게 액세스 할 수 없으므로, 일정 수준의 보안성을 제공할 수 있다. 가상화를 사용하면 물리 서버에서 리소스를 보다 효율적으로 활용할 수 있으며, 쉽게 애플리케이션을 추가하거나 업데이트할 수 있고 하드웨어 비용을 절감할 수 있어 더 나은 확장성을 제공한다. 가상화를 통해 일련의 물리 리소스를 폐기 가능한(disposable) 가상 머신으로 구성된 클러스터로 만들 수 있다.
컨테이너 개발 시대: 컨테이너는 VM과 유사하지만 격리 속성을 완화하여 애플리케이션 간에 운영체제(OS)를 공유한다. 그러므로 컨테이너는 가볍다고 여겨진다. VM과 마찬가지로 컨테이너에는 자체 파일 시스템, CPU 점유율, 메모리, 프로세스 공간 등이 있다. 기본 인프라와의 종속성을 끊었기 때문에, 클라우드나 OS 배포본에 모두 이식할 수 있다.
컨테이너는 애플리케이션을 포장하고 실행하는 좋은 방법이다. 프로덕션 환경에서는 애플리케이션을 실행하는 컨테이너를 관리하고 가동 중지 시간이 없는지 확인해야 한다. 예를 들어 컨테이너가 다운되면 다른 컨테이너를 다시 시작해야 한다. 이 문제를 시스템에 의해 처리한다면 더 쉽지 않을까? 그것이 쿠버네티스가 필요한 이유이다! 쿠버네티스는 분산 시스템을 탄력적으로 실행하기 위한 프레임 워크를 제공한다. 애플리케이션의 확장과 장애 조치를 처리하고, 배포 패턴 등을 제공한다. 예를 들어, 쿠버네티스는 시스템의 카나리아 배포를 쉽게 관리 할 수 있다.
https://kubernetes.io/ko/docs/concepts/overview/what-is-kubernetes/
쿠버네티스란?
쿠버네티스는 컨테이너화된 애플리케이션의 배포, 확장 등을 관리하는 것을 자동화하기 위한 플랫폼 (컨테이너 오케스트레이션 엔진)이다. 최근 몇 년간 도커를 시작으로 컨테이너 기술에 대한 관심이 높아지면서 실제 서비스 환경에 컨테이너를 적용하는 사례가 늘고 있다. 컨테이너 런타임 중 하나인 도커는 단독으로는 도커가 설치된 호스트 (도커 호스트)를 동시에 여러 대 동작시키거나 중앙에서 통합, 관리할 수가 없었다. 이렇게 도커 자체로는 여러 호스트로 구성되거나 일정 규모 이상의 서비스 환경에서 사용할 수 있는 시스템을 구축하기 어려우므로, 요즘에는 쿠버네티스로 대표되는 컨테이너 오케스트레이션 엔진을 사용해 이러한 시스템을 구축하는 것이 일반적이다.
쿠버네티스 완벽 가이드 (마사야 아오야마 지음, 박상욱 옮김) (길벗)
쿠버네티스의 기원
위키백과 - 쿠버네티스 - 역사
그리스어로 키잡이를 뜻하는 쿠버네티스(Kubernetes)는 조 베다(Joe Beda), Brendan Burns, Craig McLuckie에 의해 설립되었으며 Brian Grant, Tim Hockin 등 다른 구글 엔지니어들에 의해 빠르게 동참되었고 2014년 중순에 구글에 의해 처음 발표되었다. 개발과 설계는 구글의 보그(Borg) 시스템, 그리고 이전에 보그에서 일한 프로젝트의 상위 기여자 중 다수에 의해 상당한 영향을 받았다. 구글 내 쿠버네티스의 원래 코드명은 프로젝트 세븐이었으며, 이는 더 친숙한 보그 스타 트렉 캐릭터를 참조한 것이다.
쿠버네티스 v1.0은 2015년 7월 21일에 출시되었다. 쿠버네티스 v1.0 출시와 함께 구글은 리눅스 재단과 파트너십을 맺고 클라우드 네이티브 컴퓨팅 재단(Cloud Native Computing Foundation, CNCF)을 설립하였고 쿠버네티스를 시드 테크놀로지(seed technology)로 제공하였다. 2016년 2월, 쿠버네티스용 Helm 패키지 매니저가 출시되었다. 2018년 3월 6일, 쿠버네티스 프로젝트는 깃허브에서 커밋 순위 9위를 달성하였으며 개발자 및 이슈 순위에서 리눅스 커널에 이어 2위를 차지하였다. v1.18까지 쿠버네티스는 N-2 지원 정책(3개의 최근 마이너 버전이 보안 및 버그 수정을 수신함을 의미)을 준수했다. v1.19 이상부터 쿠버네티스는 N-3 지원 정책을 준수한다.
https://ko.wikipedia.org/wiki/%EC%BF%A0%EB%B2%84%EB%84%A4%ED%8B%B0%EC%8A%A4
Borg: The Predecessor to Kubernetes
Google has been running containerized workloads in production for more than a decade. Whether it's service jobs like web front-ends and stateful servers, infrastructure systems like Bigtable and Spanner, or batch frameworks like MapReduce and Millwheel, virtually everything at Google runs as a container. Today, we took the wraps off of Borg, Google’s long-rumored internal container-oriented cluster-management system, publishing details at the academic computer systems conference Eurosys. You can find the paper here.
To give you a flavor, here are four Kubernetes features that came from our experiences with Borg:
1. Pods.
A pod is the unit of scheduling in Kubernetes. It is a resource envelope in which one or more containers run. Containers that are part of the same pod are guaranteed to be scheduled together onto the same machine, and can share state via local volumes.
Borg has a similar abstraction, called an alloc (short for “resource allocation”). Popular uses of allocs in Borg include running a web server that generates logs alongside a lightweight log collection process that ships the log to a cluster filesystem (not unlike fluentd or logstash); running a web server that serves data from a disk directory that is populated by a process that reads data from a cluster filesystem and prepares/stages it for the web server (not unlike a Content Management System); and running user-defined processing functions alongside a storage shard. Pods not only support these use cases, but they also provide an environment similar to running multiple processes in a single VM -- Kubernetes users can deploy multiple co-located, cooperating processes in a pod without having to give up the simplicity of a one-application-per-container deployment model.
2. Services.
Although Borg’s primary role is to manage the lifecycles of tasks and machines, the applications that run on Borg benefit from many other cluster services, including naming and load balancing. Kubernetes supports naming and load balancing using the service abstraction: a service has a name and maps to a dynamic set of pods defined by a label selector (see next section). Any container in the cluster can connect to the service using the service name. Under the covers, Kubernetes automatically load-balances connections to the service among the pods that match the label selector, and keeps track of where the pods are running as they get rescheduled over time due to failures.
3. Labels.
A container in Borg is usually one replica in a collection of identical or nearly identical containers that correspond to one tier of an Internet service (e.g. the front-ends for Google Maps) or to the workers of a batch job (e.g. a MapReduce). The collection is called a Job, and each replica is called a Task. While the Job is a very useful abstraction, it can be limiting. For example, users often want to manage their entire service (composed of many Jobs) as a single entity, or to uniformly manage several related instances of their service, for example separate canary and stable release tracks. At the other end of the spectrum, users frequently want to reason about and control subsets of tasks within a Job -- the most common example is during rolling updates, when different subsets of the Job need to have different configurations.
Kubernetes supports more flexible collections than Borg by organizing pods using labels, which are arbitrary key/value pairs that users attach to pods (and in fact to any object in the system). Users can create groupings equivalent to Borg Jobs by using a “job:<jobname>” label on their pods, but they can also use additional labels to tag the service name, service instance (production, staging, test), and in general, any subset of their pods. A label query (called a “label selector”) is used to select which set of pods an operation should be applied to. Taken together, labels and replication controllers allow for very flexible update semantics, as well as for operations that span the equivalent of Borg Jobs.
4. IP-per-Pod.
In Borg, all tasks on a machine use the IP address of that host, and thus share the host’s port space. While this means Borg can use a vanilla network, it imposes a number of burdens on infrastructure and application developers: Borg must schedule ports as a resource; tasks must pre-declare how many ports they need, and take as start-up arguments which ports to use; the Borglet (node agent) must enforce port isolation; and the naming and RPC systems must handle ports as well as IP addresses.
Thanks to the advent of software-defined overlay networks such as flannel or those built into public clouds, Kubernetes is able to give every pod and service its own IP address. This removes the infrastructure complexity of managing ports, and allows developers to choose any ports they want rather than requiring their software to adapt to the ones chosen by the infrastructure. The latter point is crucial for making it easy to run off-the-shelf open-source applications on Kubernetes--pods can be treated much like VMs or physical hosts, with access to the full port space, oblivious to the fact that they may be sharing the same physical machine with other pods.
https://kubernetes.io/blog/2015/04/borg-predecessor-to-kubernetes/
쿠버네티스 기능
기능 1. 선언적 코드를 사용한 관리, IaC
쿠버네티스 완벽 가이드
쿠버네티스는 YAML 형식이나 JSON 형식으로 작성한 선언적 코드(매니페스트)를 통해 배포하는 컨테이너로 주변 리소스를 관리할 수 있어 IaC를 구현할 수 있다.
쿠버네티스 완벽 가이드 (마사야 아오야마 지음, 박상욱 옮김) (길벗)
파일시스템이 호스팅 하는 스태틱 파드 매니페스트
매니페스트는 특정 디렉터리에 있는 JSON 이나 YAML 형식의 표준 파드 정의이다. kubelet 구성 파일의 staticPodPath: <the directory> 필드를 사용하자. 명시한 디렉터리를 정기적으로 스캔하여, 디렉터리 안의 YAML/JSON 파일이 생성되거나 삭제되었을 때 스태틱 파드를 생성하거나 삭제한다. Kubelet 이 특정 디렉터리를 스캔할 때 점(.)으로 시작하는 단어를 무시한다는 점을 유의하자.
https://kubernetes.io/ko/docs/tasks/configure-pod-container/static-pod/#configuration-files
매니페스트 파일
매니페스트 파일(manifest file)은 컴퓨팅에서 집합의 일부 또는 논리정연한 단위인 파일들의 그룹을 위한 메타데이터를 포함하는 파일이다. 예를 들어, 컴퓨터 프로그램의 파일들은 이름, 버전 번호, 라이선스, 프로그램의 구성 파일들을 가질 수 있다. 이 용어는 화물 목록(ship manifest)이 선원 및 화물을 나열하는 화물 수송 절차로부터 가져온 것이다.
https://ko.wikipedia.org/wiki/%EB%A7%A4%EB%8B%88%ED%8E%98%EC%8A%A4%ED%8A%B8_%ED%8C%8C%EC%9D%BC
기능 2. 스케일링 / 오토 스케일링
컨테이너 클러스터를 구성해 여러 노드를 관리하는데,
같은 컨테이너 이미지를 기반으로 여러 컨테이너 레플리카를 배포해 부하 분산이 가능하다.
부하에 따라 컨테이너 레플리카 수를 자동으로 조절하는 오토 스케일링이 가능하다.
쿠버네티스 클러스터(Kubernetes cluster)란?
쿠버네티스 클러스터는 애플리케이션 컨테이너를 실행하기 위한 일련의 노드 머신입니다. 쿠버네티스를 실행 중이라면 클러스터를 실행하고 있는 것입니다. 최소 수준에서 클러스터는 컨트롤 플레인 및 하나 이상의 컴퓨팅 머신 또는 노드를 포함하고 있습니다. 컨트롤 플레인은 어느 애플리케이션을 실행하고 애플리케이션이 어느 컨테이너 이미지를 사용할지와 같이 클러스터를 원하는 상태로 유지 관리합니다. 노드는 애플리케이션과 워크로드를 실제로 실행합니다. 클러스터는 쿠버네티스의 핵심 장점입니다. 즉 물리 머신, 가상 머신, 온프레미스, 클라우드에 구애받지 않고 머신 그룹 전체에서 컨테이너를 예약하고 실행할 수 있습니다. 쿠버네티스 컨테이너는 개별 머신에 연결되지 않습니다. 대신에 클러스터 전체에서 추상화됩니다.
https://www.redhat.com/ko/topics/containers/what-is-a-kubernetes-cluster
Kubernetes - Kubernetes란? (클러스터,노드,파드(pod), 리플리카셋, 디플로이먼트)
쿠버네티스 클러스터는 쿠버네티스의 여러 리소스를 관리하기 위한 집합체를 말한다. 여타 엘라스틱서치, 레디스 등 많은 미들웨어에서 사용하는 클러스터라는 용어와 크게 다르지 않다.
쿠버네티스 리소스 중에서 가장 큰 개념은 노드(node)이다. 노드는 클러스터의 관리 대상으로 등록된 도커 호스트로, 도커 컨테이너가 배치되는 대상이다. 그리고 쿠버네티스 클러스터 전체를 관리하는 서버인 마스터가 적어도 하나 이상 있어야한다. 여기서 하나 이상이라는 말은 클러스터가 작동하기 위한 최소 조건이지만 실제 프러덕 환경에서는 절대 하나로 클러스터를 구성하지 않는다. 최소 3개 이상의 마스터 노드를 갖는 것이 좋다.
파드는 컨테이너가 모인 집합체의 단위로, 적어도 하나 이상의 컨테이너로 이루어진다. 여기서 말하는 컨테이너는 도커 컨테이너를 이야기한다. 쿠버네티스를 도커와 함께 사용한다면 파드는 컨테이너 하나 혹은 컨테이너의 집합체가 된다. 쿠버네티스에서는 결합이 강한 컨테이너를 파드로 묶어 일괄 배포한다.(ex spring web app + nginx)
출처: https://coding-start.tistory.com/308 [코딩스타트]
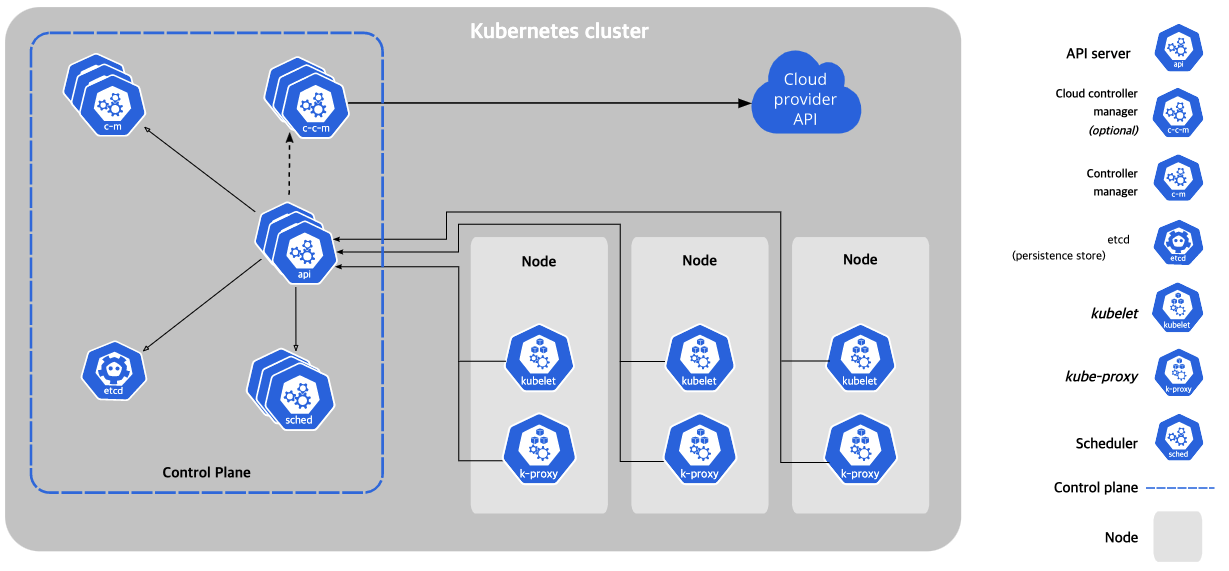
쿠버네티스 컴포넌트
쿠버네티스를 배포하면 클러스터를 얻는다.
쿠버네티스 클러스터는 컨테이너화된 애플리케이션을 실행하는 노드라고 하는 워커 머신의 집합.
모든 클러스터는 최소 한 개의 워커 노드를 가진다. 워커 노드는 애플리케이션의 구성요소인 파드를 호스트한다.
컨트롤 플레인은 워커 노드와 클러스터 내 파드를 관리한다.
프로덕션 환경에서는 일반적으로 컨트롤 플레인이 여러 컴퓨터에 걸쳐 실행되고,
클러스터는 일반적으로 여러 노드를 실행하므로 내결함성과 고가용성이 제공된다.
https://kubernetes.io/ko/docs/concepts/overview/components/
기능 3. 스케줄링
스케줄링 단계에서는, 어떤 쿠버네티스 노드에 컨테이너를 배포할 지를 결정한다.
어피니티, 안티어피니티 기능을 활용해 어플리케이션 워크로드 특징과 노드 성능을 반영해 스케줄링을 진행한다고 한다.
퍼블릭 클라우드 서비스 등에 쿠버네티스 클러스터를 구축했다면, 노드의 가용영역 등을 식별하는 추가 정보로 부여되어,
고가용성을 위한 멀티존 분산 배치도 가능하다.
노드 어피니티
노드 어피니티는 개념적으로 nodeSelector 와 비슷하다 --
이는 노드의 레이블을 기반으로 파드를 스케줄할 수 있는 노드를 제한할 수 있다.
여기에 현재 requiredDuringSchedulingIgnoredDuringExecution 와
preferredDuringSchedulingIgnoredDuringExecution 로 부르는 두 가지 종류의 노드 어피니티가 있다.
전자는 파드가 노드에 스케줄되도록 반드시 규칙을 만족해야 하는 것
(nodeSelector 와 비슷하나 보다 표현적인 구문을 사용해서)을 지정하고,
후자는 스케줄러가 시도하려고는 하지만, 보증하지 않는 선호(preferences) 를 지정한다는 점에서
이를 각각 "엄격함(hard)" 과 "유연함(soft)" 으로 생각할 수 있다.
이름의 "IgnoredDuringExecution" 부분은 nodeSelector 작동 방식과 유사하게
노드의 레이블이 런타임 중에 변경되어 파드의 어피니티 규칙이 더 이상 충족되지 않으면 파드가 그 노드에서 동작한다는 의미이다.
향후에는 파드의 노드 어피니티 요구 사항을 충족하지 않는 노드에서 파드를 제거한다는 점을 제외하고는 requiredDuringSchedulingIgnoredDuringExecution 와 동일한 requiredDuringSchedulingRequiredDuringExecution 를 제공할 계획이다. 따라서 requiredDuringSchedulingIgnoredDuringExecution 의 예로는 "인텔 CPU가 있는 노드에서만 파드 실행"이 될 수 있고, preferredDuringSchedulingIgnoredDuringExecution 의 예로는 "장애 조치 영역 XYZ에 파드 집합을 실행하려고 하지만, 불가능하다면 다른 곳에서 일부를 실행하도록 허용"이 있을 것이다. 노드 어피니티는 PodSpec의 affinity 필드의 nodeAffinity 필드에서 지정된다.
https://kubernetes.io/ko/docs/concepts/scheduling-eviction/assign-pod-node/#%EB%85%B8%EB%93%9C-%EC%96%B4%ED%94%BC%EB%8B%88%ED%8B%B0
쿠버네티스 #24 - Pod 스케쥴링 #2 Affinity
Affinity Taint가 Pod가 배포되지 못하도록 하는 정책이라면,
affinity는 Pod를 특정 Node에 배포되도록 하는 정책이다. affinity는 Node를 기준으로 하는 Node affinity와, 다른 Pod가 배포된 위치(node) 를 기준으로 하는 Pod affinity 두 가지가 있다.
Node affinity
Node affinity는 Pod가 특정 node로 배포되도록 하는 기능이다.
예전에 label에서 설명했던 node selector 도 node의 label과 pod의 selector label이 매칭되는 node에만 배포하도록 하기 때문에, 사실상 Node affinity와 같은 기능을 한다. Node affinity는 Hard affinity와 Soft affinity가 있다. Node affinity는 Pod가 조건이 딱 맞는 node 에만 배포되도록 하는 기능이고, Soft affinity는 Pod가 조건에 맞는 node에 되도록(반드시가 아니라)이면 배포되도록 하는 기능이다. 앞에서 언급한 node selector는 Hard affinity에 해당한다.
Node affinity는 여러 affinity를 동시에 적용할 수 있는데, 위의 예제에서는 두 개의 Affinity를 정의하였다. 두번째 Affinity는 Soft affinity로, preferredDuringSchedulingIgnoredDuringExecution: 으로 정의한다. Soft affinity는 앞서 언급한것과 같이 조건에 맞는 node로 되도록이면 배포될 수 있도록 그 node로 배포 선호도를 주는 기능이다. 이때 weight 필드를 이용해서 선호도를 조정할 수 있는데, weight은 1~100이고, node 의 soft affinity의 weight 값들을 합쳐서 그 값이 높은 node를 우선으로 고려하도록 우선 순위를 주는데 사용할 수 있다.
특정 Node로 배포되게 하는 Affinity 설정도 있지만,
반대로 특정 Node로 배포되는 것을 피하도록 하는 AntiAffinity라는 설정도 있다.
nodeAffinity 대신 nodeAntiAffinity라는 Notation을 사용하면 되고,
Affinity와는 다르게 반대로, 조건에 맞는 Node를 피해서 배포하도록 된다.
출처: https://bcho.tistory.com/1346 [조대협의 블로그]
쿠버네티스 스케줄러
쿠버네티스 스케줄러
쿠버네티스에서 스케줄링 은 Kubelet이 파드를 실행할 수 있도록 파드가 노드에 적합한지 확인하는 것을 말한다.
(Kubelet="클러스터의 각 노드에서 실행되는 에이전트. Kubelet은 파드에서 컨테이너가 확실하게 동작하도록 관리한다.")
스케줄링 개요
스케줄러는 노드가 할당되지 않은 새로 생성된 파드를 감시한다. 스케줄러가 발견한 모든 파드에 대해 스케줄러는 해당 파드가 실행될 최상의 노드를 찾는 책임을 진다. 스케줄러는 아래 설명된 스케줄링 원칙을 고려하여 이 배치 결정을 하게 된다.
https://kubernetes.io/ko/docs/concepts/scheduling-eviction/kube-scheduler/
기능 4. 리소스 관리
따로 사용자가 컨테이너를 지정해서 배치하지 않는 한, 쿠버네티스의 노드는 리소스 상태에 따라 스케줄링된다.
사용자는 따라서 어떤 노드에 어떤 컨테이너를 배치할지 별도로 관리할 필요가 크지 않다.
리소스 사용 상태에 따라 오토 스케일링도 구현되어 노드를 자동으로 추가하거나 삭제할 수 있다.
쿠버네티스 #21 - 리소스(CPU/Memory) 할당과 관리
리소스 관리 쿠버네티스에서 Pod를 어느 노드에 배포할지를 결정하는 것을 스케쥴링이라고 한다.
Pod에 대한 스케쥴링시에, Pod내의 애플리케이션이 동작할 수 있는 충분한 자원 (CPU,메모리 등)이 확보되어야 한다.
쿠버네티스 입장에서는 애플리케이션에서 필요한 자원의 양을 알아야, 그 만한 자원이 가용한 노드에 Pod를 배포할 수 있다.
쿠버네티스에서는 이런 컨셉을 지원하기 위해서 컨테이너에 필요한 리소스의 양을 명시할 수 있도록 지원하고 있다.
현재(1.9 버전) 지원되는 리소스 타입은 CPU와 메모리이며, 아직 까지는 네트워크 대역폭이나 다른 리소스 타입은 지원하고 있지 않다.
출처: https://bcho.tistory.com/1291 [조대협의 블로그]
컨테이너 리소스 관리
컨테이너 리소스 관리 파드를 지정할 때, 컨테이너에 필요한 각 리소스의 양을 선택적으로 지정할 수 있다. 지정할 가장 일반적인 리소스는 CPU와 메모리(RAM) 그리고 다른 것들이 있다. 파드에서 컨테이너에 대한 리소스 요청(request) 을 지정하면, 스케줄러는 이 정보를 사용하여 파드가 배치될 노드를 결정한다. 컨테이너에 대한 리소스 제한(limit) 을 지정하면, kubelet은 실행 중인 컨테이너가 설정한 제한보다 많은 리소스를 사용할 수 없도록 해당 제한을 적용한다. 또한 kubelet은 컨테이너가 사용할 수 있도록 해당 시스템 리소스의 최소 요청 량을 예약한다.
https://kubernetes.io/ko/docs/concepts/configuration/manage-resources-containers/
기능 5. 자동화된 복구
오류가 발생해도 서비스가 원활히 돌아가도록 하는 다중화, 고가용성 측면에서,
쿠버네티스의 중요한 특징은 복구 자동화이다.
컨테이너를 모니터링하고 프로세스가 멈춘 것이 감지되면 자동적으로 다시 스케줄링해 재배포한다.
클러스터 노드 상의 장애 등의 경우 노드 컨테이너가 사라지더라도 서비스에 영향이 없도록 자동으로 복구하는 것이다.
자동 복구 실행 조건에는 프로세스 모니터링 외에도 헬스 체크 성공 여부 등을 활용할 수 있다고 한다.
Using kubectl to Create a Deployment
Once the application instances are created, a Kubernetes Deployment Controller continuously monitors those instances. If the Node hosting an instance goes down or is deleted, the Deployment controller replaces the instance with an instance on another Node in the cluster. This provides a self-healing mechanism to address machine failure or maintenance.
https://kubernetes.io/docs/tutorials/kubernetes-basics/deploy-app/_print/#pg-2b1bba431989008c7493109a0f049ece
쿠버네티스 #13 - 모니터링 (1/2)
쿠버네티스 모니터링 컨셉 쿠버네티스에 대한 모니터링을 보면 많은 툴과 지표들이 있어서 혼돈하기 쉬운데, 먼저 모니터링 컨셉에 대한 이해를 할 필요가 있다. 쿠버네티스 기반의 시스템을 모니터링하기 위해서는 크게 아래와 같이 4가지 계층을 모니터링해야 한다.
1. 호스트 (노드)
먼저 쿠버네티스 컨테이너를 실행하는 하드웨어 호스트 즉 노드에 대한 지표 모니터링이 필요하다. 노드의 CPU,메모리, 디스크, 네트워크 사용량과, 노드 OS와 커널에 대한 모니터링이 이에 해당한다.
2. 컨테이너
다음은 노드에서 기동되는 각각의 컨테이너에 대한 정보이다. 컨테이너의 CPU,메모리, 디스크, 네트워크 사용량등을 모니터링 한다.
3. 애플리케이션
컨테이너안에서 구동되는 개별 애플리케이션의 지표를 모니터링 한다. 예를 들어, 컨테이너에서 기동되는 node.js 기반의 애플리케이션의 응답시간, HTTP 에러 빈도등을 모니터링한다.
4. 쿠버네티스
마지막으로, 컨테이너를 컨트롤 하는 쿠버네티스 자체에 대한 모니터링을한다. 쿠버네티스의 자원인 서비스나 POD, 계정 정보등이 이에 해당한다. 쿠버네티스 기반의 시스템 모니터링에 대해서 혼돈이 오는 부분중의 하나가 모니터링이라는 개념이 포괄적이기 때문이다. 우리가 여기서 다루는 모니터링은 자원에 대한 지표 대한 모니터링이다. 포괄적인 의미의 모니터링은 로그와, 에러 모니터링등 다양한 내용을 포괄한다.
출처: https://bcho.tistory.com/1269 [조대협의 블로그]
쿠버네티스 #9 - HealthCheck
쿠버네티스는 각 컨테이너의 상태를 주기적으로 체크해서, 문제가 있는 컨테이너를 자동으로 재시작하거나 또는 문제가 있는 컨테이너(Pod를) 서비스에서 제외할 수 있다. 이러한 기능을 헬쓰 체크라고 하는데, 크게 두가지 방법이 있다. 컨테이너가 살아 있는지 아닌지를 체크하는 방법이 Liveness probe 그리고 컨테이너가 서비스가 가능한 상태인지를 체크하는 방법을 Readiness probe 라고 한다.
출처: https://bcho.tistory.com/1264 [조대협의 블로그]
[Kubernetes] Pod #2: 쿠버네티스 셀프 힐링 및 자원 할당
쿠버네티스는 장애가 생기는 컨테이너가 있는지, 또 있다면 재시작을 하기 위해서 등 컨테이너가 실행된 후에도 주기적으로 kubelet을 이용해 컨테이너를 진단합니다. 이때 필요한 프로브가 두 가지가 있습니다.
livenessProbe : 컨테이너가 실행됐는지 확인합니다. 만약 이 진단에 실패하면 kubelet는 컨테이너를 종료시키고 재시작 정책에 따라 컨테이너를 재시작합니다.
readinessProbe : 컨테이너가 실행된 후 실제로 서비스 요청에 응답할 수 있는지 진단합니다. readinessProbe를 지원하는 컨테이너는 컨테이너가 실행된 다음 트래픽을 받지 않고, 실제 트래픽을 받을 준비가 되었을 때 트래픽을 받게 됩니다. readinessProbe는 자바 애플리케이션처럼 프로세스가 시작된 후 앱이 초기화될 때까지 시간이 걸리는 컨테이너에 유용하게 작용합니다.
그런데 만약 readinessProbe 진단이 실패하면 엔드포인트 컨트롤러는 해당 파드에 연결된 모든 서비스를 대상으로 엔드포인트 정보를 제거합니다.
컨테이너의 진단은 컨테이너가 구현한 핸들러(handler)를 kubelet이 호출해서 실행하게 됩니다.
ExecAction : 컨테이너 안에 지정된 명령을 실행 → 종료 코드가 0이면 Success라고 진단
TCPSocketAction : 컨테이너 안에 지정된 IP와 포트로 TCP 상태를 확인 → 포트가 열려있으면 Success라고 진단
HTTPGetAction : 컨테이너 안에 지정된 IP, 포트, 경로로 HTTP GET 요청을 보내서 확인 → 응답 상태 코드가 200~400 사이면 Success라고 진단
진단 결과로는 진단을 성공적으로 마쳤다는 Success와 진단을 실패한 Failure,
그리고 진단 자체가 실패해서 컨테이너 상태를 알 수 없는 Unknown이 있습니다.
https://ooeunz.tistory.com/120
기능 6. 로드 밸런싱과 서비스 디스커버리
애플리케이션을 사용자가 접속해서 사용하도록 하려면 엔드포인트를 준비해서 할당해야 한다.
가상 머신을 사용하면 로드밸런서를 통해 여러 가상 머신들에게 라우팅되도록 구성해줄 수 있다.
그리고 그 로드밸런서 주소를 엔드포인트로 설정하면 된다.
엔드포인트란
엔드포인트를 막연하게 요청이 최종적으로 도달할 URI로 생각하고 있다.
an endpoint is simply one end of a communication channel. (stackoverflow)
벌써 정답이 나온듯하다. 커뮤니케이션 채널의 한 쪽 끝이라니.
엔드포인트는 서비스를 사용가능하도록 하는 서비스에서 제공하는 커뮤니케이션 채널의 한쪽 끝.
즉 요청을 받아 응답을 제공하는 서비스를 사용할 수 있는 지점을 의미한다.
https://toneyparky.tistory.com/6
쿠버네티스는 로드밸런서 기능을 제공하고 있고, 사전에 미리 조건을 정의해두면, 그에 맞는 컨테이너 그룹으로 라우팅하는 엔드포인트 설정도 가능하다고 한다. 컨테이너 확장 시에도 엔드포인트 서비스에 컨테이너를 자동으로 등록하거나 삭제할 수도 있는 등 작업이 자동화되어 있다.
쿠버네티스 완벽 가이드 책에서는 괄호 열고 <서비스나 인그레스>라고 표현을 해두어 찾아보기로 했다.
쿠버네티스 서비스(Service) 개념 정리
포드가 다른 곳에서 제공하는 서비스를 사용하려면 다른 포드를 찾을 방법이 필요합니다. 그러나 클라이언트가 서비스를 제공하는 서버의 IP 주소나 호스트 이름을 지정하는 일반적인 애플리케이션과 달리 쿠버네티스에선 포드가 일회성이라 언제든지 이동하거나 사라질 수 있기 때문에 포드를 연결하기 위한 단일 진입 점이 필요합니다. 이런 문제를 해결하기 위해 쿠버네티스에선 변하지 않는 IP 주소와 포트를 제공하는 서비스(Service) 라는 리소스를 제공합니다. 그리하여 클라이언트는 해당 IP 및 포트에 연결하여 포드 중 하나와 통신할 수 있게 됩니다. 이번 챕터에선 서비스가 어떻게 생성되는지 보면서 자세히 알아보겠습니다.
https://blog.eunsukim.me/posts/kubernetes-service-overview
쿠버네티스 #7 서비스 (service)
Service 쿠버네티스 서비스에 대해서 자세하게 살펴보도록 한다. Pod의 경우에 지정되는 Ip가 랜덤하게 지정이 되고 리스타트 때마다 변하기 때문에 고정된 엔드포인트로 호출이 어렵다, 또한 여러 Pod에 같은 애플리케이션을 운용할 경우 이 Pod 간의 로드밸런싱을 지원해줘야 하는데, 서비스가 이러한 역할을 한다. 서비스는 지정된 IP로 생성이 가능하고, 여러 Pod를 묶어서 로드 밸런싱이 가능하며, 고유한 DNS 이름을 가질 수 있다.
출처: https://bcho.tistory.com/1262 [조대협의 블로그]
서비스
파드 집합에서 실행중인 애플리케이션을 네트워크 서비스로 노출하는 추상화 방법 쿠버네티스를 사용하면 익숙하지 않은 서비스 디스커버리 메커니즘을 사용하기 위해 애플리케이션을 수정할 필요가 없다. 쿠버네티스는 파드에게 고유한 IP 주소와 파드 집합에 대한 단일 DNS 명을 부여하고, 그것들 간에 로드-밸런스를 수행할 수 있다.
https://kubernetes.io/ko/docs/concepts/services-networking/service/
인그레스(Ingress)
클러스터 내의 서비스에 대한 외부 접근을 관리하는 API 오브젝트이며, 일반적으로 HTTP를 관리함. 인그레스는 부하 분산, SSL 종료, 명칭 기반의 가상 호스팅을 제공할 수 있다.
이 가이드는 용어의 명확성을 위해 다음과 같이 정의한다.
노드(Node): 클러스터의 일부이며, 쿠버네티스에 속한 워커 머신.
클러스터(Cluster): 쿠버네티스에서 관리되는 컨테이너화 된 애플리케이션을 실행하는 노드 집합. 이 예시와 대부분의 일반적인 쿠버네티스 배포에서 클러스터에 속한 노드는 퍼블릭 인터넷의 일부가 아니다.
에지 라우터(Edge router): 클러스터에 방화벽 정책을 적용하는 라우터. 이것은 클라우드 공급자 또는 물리적 하드웨어의 일부에서 관리하는 게이트웨이일 수 있다.
클러스터 네트워크(Cluster network): 쿠버네티스 네트워킹 모델에 따라 클러스터 내부에서 통신을 용이하게 하는 논리적 또는 물리적 링크 집합.
서비스: 레이블 셀렉터를 사용해서 파드 집합을 식별하는 쿠버네티스 서비스. 달리 언급하지 않으면 서비스는 클러스터 네트워크 내에서만 라우팅 가능한 가상 IP를 가지고 있다고 가정한다.
인그레스란? 인그레스는 클러스터 외부에서 클러스터 내부 서비스로 HTTP와 HTTPS 경로를 노출한다. 트래픽 라우팅은 인그레스 리소스에 정의된 규칙에 의해 컨트롤된다.
로드 밸런싱
인그레스 컨트롤러는 로드 밸런싱 알고리즘, 백엔드 가중치 구성표 등 모든 인그레스에 적용되는 일부 로드 밸런싱 정책 설정으로 부트스트랩된다. 보다 진보된 로드 밸런싱 개념 (예: 지속적인 세션, 동적 가중치)은 아직 인그레스를 통해 노출되지 않는다. 대신 서비스에 사용되는 로드 밸런서를 통해 이러한 기능을 얻을 수 있다. 또한, 헬스 체크를 인그레스를 통해 직접 노출되지 않더라도, 쿠버네티스에는 준비 상태 프로브와 같은 동일한 최종 결과를 얻을 수 있는 병렬 개념이 있다는 점도 주목할 가치가 있다. 컨트롤러 별 설명서를 검토하여 헬스 체크를 처리하는 방법을 확인한다(예: nginx, 또는 GCE).
https://kubernetes.io/ko/docs/concepts/services-networking/ingress/
162. [Kubernetes] 1편 : 쿠버네티스 Ingress 개념 및 사용 방법, 온-프레미스 환경에서 Ingress 구축하기
쿠버네티스 인그레스 (Ingress) 란 일반적으로, 네트워크 트래픽은 Ingress와 egress (잘 사용하지는 않는 단어이긴 하지만) 으로 구분된다. Ingress는 외부로부터 서버 내부로 유입되는 네트워크 트래픽을, egress는 서버 내부에서 외부로 나가는 트래픽을 의미한다. 쿠버네티스에도 Ingress라고 하는 리소스 오브젝트가 존재한다. 쿠버네티스의 Ingress는 외부에서 쿠버네티스 클러스터 내부로 들어오는 네트워크 요청 : 즉, Ingress 트래픽을 어떻게 처리할지 정의한다. 쉽게 말하자면, Ingress는 외부에서 쿠버네티스에서 실행 중인 Deployment와 Service에 접근하기 위한, 일종의 관문 (Gateway) 같은 역할을 담당한다.
Ingress를 사용하지 않았다고 가정했을 때, 외부 요청을 처리할 수 있는 선택지는 NodePort, ExternalIP 등이 있을 수 있겠다. 그러나 이러한 방법들은 일반적으로 Layer 4 (TCP, UDP) 에서의 요청을 처리하며, 네트워크 요청에 대한 세부적인 처리 로직을 구현하기는 아무래도 한계가 있다. 쿠버네티스의 Ingress는 Layer 7에서의 요청을 처리할 수 있다. 예컨대, 외부로부터 들어오는 요청에 대한 로드 밸런싱, TLS/SSL 인증서 처리, 특정 HTTP 경로의 라우팅 등을 Ingress를 통해 자세하게 정의할 수 있다. 물론, 이러한 기능들은 위에서 언급한 NodePort 등의 방법으로도 절대로 불가능한 것은 아니지만, 이러한 세부적인 로직을 모든 애플리케이션 개발 레벨에서 각각 구현하게 되면 서비스 운영 측면에서 추가적인 복잡성이 발생한다. 그 대신에, 외부 요청을 어떻게 처리할 것인지를 정의하는 집합인 Ingress를 정의한 뒤, 이를 Ingress Controller라고 부르는 특별한 웹 서버에 적용함으로써 추상화된 단계에서 서비스 처리 로직을 정의할 수 있다.
https://blog.naver.com/alice_k106/221502890249
서비스 디스커버리도 가능하다고 한다.
컨테이너 기반 시스템 구축 시 기능별로 독립된 소규모 애플리케이션을 연계하는 MSA 구조가 일반적인데,
이럴 경우 서로의 마이크로서비스를 참조할 때 유용한 기능이라고 한다.
[k8s] 스케쥴링과 서비스 디스커버리
서비스 디스커버리
일반적인 웹 애플리케이션의 경우 리퀘스트를 받은 프론트엔드 애플리케이션이 사용자의 트랜잭션을 처리하기 위해 백엔드 서비스를 호출합니다. 이 때 디플로이된 애플리케이션이 어디에 있는지를 찾아내는 장치를 서비스 디스커버리라고 합니다. 쿠버네티스에서는 클러스터 안에 구성 레지스트리를 갖고 있어서 이를 바탕으로 서비스 디스커버리를 동적으로 수행합니다. 마이크로 서비스형 애플리케이션의 경우 작은 기능을 제공하는 수많은 서비스를 조합하여 하나의 시스템을 만듭니다. 이 때 서비스 간의 호출은 서비스 디스커버리가 수행합니다.
https://kimjingo.tistory.com/m/117
쿠버네티스 서비스(Service) 개념 정리
서비스 디스커버리 서비스를 생성하면 포드에게 액세스할 수 있는 단일 진입점이 생성되었단 것을 알려주어야 하는데, 사람이 직접 설정할 필요 없이 쿠버네티스는 포드가 서비스의 IP 와 포트번호를 알아낼 수 있는 두 가지 방법을 제공합니다. 첫 번째로 쿠버네티스는 포드가 시작되면 그 순간 존재하는 각 서비스들을 가리키는 환경 변수를 세팅합니다. 즉, 포드를 생성하기 전에 서비스를 생성했다면 포드는 환경 변수를 조사해서 서비스의 IP 주소와 포트 번호를 알아낼 수 있습니다. 그러나 포드가 생성된 이후 서비스가 생성된다면 환경변수는 아직 설정되지 않는데, 이 경우 두 번째 방법인 DNS로 서비스를 찾을 수 있습니다.
https://blog.eunsukim.me/posts/kubernetes-service-overview
서비스 디스커버리 하기
서비스 디스커버리하기 쿠버네티스는 서비스를 찾는 두 가지 기본 모드를 지원한다. - 환경 변수와 DNS
환경 변수
파드가 노드에서 실행될 때, kubelet은 각 활성화된 서비스에 대해 환경 변수 세트를 추가한다. 도커 링크 호환 변수 (makeLinkVariables 참조)와 보다 간단한 {SVCNAME}_SERVICE_HOST 및 {SVCNAME}_SERVICE_PORT 변수를 지원하고, 이때 서비스 이름은 대문자이고 대시는 밑줄로 변환된다.
DNS
애드-온을 사용하여 쿠버네티스 클러스터의 DNS 서비스를 설정할 수(대개는 필수적임) 있다. CoreDNS와 같은, 클러스터-인식 DNS 서버는 새로운 서비스를 위해 쿠버네티스 API를 감시하고 각각에 대한 DNS 레코드 세트를 생성한다. 클러스터 전체에서 DNS가 활성화된 경우 모든 파드는 DNS 이름으로 서비스를 자동으로 확인할 수 있어야 한다. 예를 들면, 쿠버네티스 네임스페이스 my-ns에 my-service라는 서비스가 있는 경우, 컨트롤 플레인과 DNS 서비스가 함께 작동하여 my-service.my-ns에 대한 DNS 레코드를 만든다. my-ns 네임 스페이스의 파드들은 my-service(my-service.my-ns 역시 동작함)에 대한 이름 조회를 수행하여 서비스를 찾을 수 있어야 한다. 다른 네임스페이스의 파드들은 이름을 my-service.my-ns으로 사용해야 한다. 이 이름은 서비스에 할당된 클러스터 IP로 변환된다. 쿠버네티스는 또한 알려진 포트에 대한 DNS SRV (서비스) 레코드를 지원한다. my-service.my-ns 서비스에 프로토콜이 TCP로 설정된 http라는 포트가 있는 경우, IP 주소와 http에 대한 포트 번호를 검색하기 위해 _http._tcp.my-service.my-ns 에 대한 DNS SRV 쿼리를 수행할 수 있다. 쿠버네티스 DNS 서버는 ExternalName 서비스에 접근할 수 있는 유일한 방법이다. DNS 파드와 서비스에서 ExternalName 검색에 대한 자세한 정보를 찾을 수 있다.
https://kubernetes.io/ko/docs/concepts/services-networking/service/#%EC%84%9C%EB%B9%84%EC%8A%A4-%EB%94%94%EC%8A%A4%EC%BB%A4%EB%B2%84%EB%A6%AC%ED%95%98%EA%B8%B0
기능 7. 데이터 관리
쿠버네티스는 백엔드 데이터를 etcd에 보관한다.
etcd는 클러스터를 구성해 이중화가 가능하다.
컨테이너 설정 파일 및 인증 정보 등 데이터도 저장해 안전한 관리를 가능케 한다.
다양한 미들웨어도 쿠버네티스를 지원한다.
Ansible(배포), Apache Ignite(서비스 디스커버리 기반 클러스터 생성, 스케일링), Fluentd(로그 전송), Gitlab(CI/CD), Jenkins(배포), Openstack(구축), Prometheus(모니터링), Spark(실행), Spinnaker(배포), Kubeflow(ML 배포), Rook(분산 파일시스템 배포), Vitess(MySQL 배포) 등이 있다고 한다.
etcd
etcd
모든 클러스터 데이터를 담는 쿠버네티스 뒷단의 저장소로 사용되는 일관성·고가용성 키-값 저장소. 쿠버네티스 클러스터에서 etcd를 뒷단의 저장소로 사용한다면, 이 데이터를 백업하는 계획은 필수이다. etcd에 대한 자세한 정보는, 공식 문서를 참고한다.
https://www.redhat.com/ko/topics/containers/what-is-etcd
https://kubernetes.io/ko/docs/concepts/overview/components/#etcd
Documentation versions
A distributed, reliable key-value store for the most critical data of a distributed system
etcd.io
쿠버네티스의 Etcd 살펴보기
etcd etcd 는 분산 시스템에서 사용할 수 있는 분산형 키-값 (key-value) 저장소 입니다 CoreOS에서 클러스터를 관리하기 위해서 사용했으며, 요즘은 쿠버네티스의 기본 데이터 저장소로 많이 사용하고 있습니다. etcd는 고가용성을 위하여 클러스터로 설치됩니다. 여러 노드의 통신은 래프트(Raft) 알고리즘에 의해 처리합니다. 연결된 노드들 중 리더를 선정하여 클러스터를 관리합니다. 데이터는 분산되어 저장하기 때문에 시스템 오류에 대한 내성을 가지고 있습니다. 클러스터의 노드는 홀수개로 이루어져야 하며, 최소 3개 이상의 노드가 필요합니다.
쿠버네티스는 etcd를 기본 데이터 저장소로 사용합니다. 그래서 쿠버네티스를 설치하기 위해서는 etcd 가 필요합니다. 별도의 etcd 클러스터를 쿠버네티스 외부에 설치한 후 쿠버네티스에서 사용할 수 있습니다. 또는 쿠버네티스를 설치할때 컨트롤플레인 노드에 etcd를 포드로 같이 설치할 수 있습니다.
'기술 공부 > 쿠버네티스' 카테고리의 다른 글
| 쿠버네티스 (3) | 파드, 레이블, 네임스페이스, 어노테이션 (0) | 2022.02.07 |
|---|---|
| 쿠버네티스 (2) | 도커와 쿠버네티스 튜토리얼 (0) | 2022.02.06 |
| 쿠버네티스 (1-5) | 쿠버네티스 소개 (0) | 2022.02.02 |
| 쿠버네티스 (1-4-2) | 개발자가 바라보는 도커의 필요성 (0) | 2022.01.18 |
| 쿠버네티스 (1-4-1) | 도커 네트워크와 의존성 문제 (0) | 2022.01.18 |