앞으로의 스터디 내용은 <Kubernetes in Action>을 기반으로 진행합니다.
자세한 내용은, 해당 책을 확인해주세요!
http://www.yes24.com/Product/Goods/89607047
14장 핵심 내용
- 컨테이너의 CPU, 메모리 및 컴퓨팅 리소스 요청
- CPU, 메모리 제한 설정
- 파드 서비스 품질 보장
- 네임스페이스에서 파드의 기본 / 최소 / 최대 리소스 설정
- 네임스페이스에서 사용 가능한 리소스 총량 제한
파드 컨테이너의 리소스 요청
리소스 요청을 갖는 파드 생성
- 컨테이너의 CPU, 메모리 필요량(requests), 제한량(limits)을 지정.
- 컨테이너 개별 지정량으로 파드 전체에 지정되지 않음. 파드 리소스 요청량/필요량과 제한량은 전체 컨테이너의 합계.
- CPU 요청의 지정 = 컨테이너의 프로세스에 할당되는 CPU 시간의 요청 = 최소한의 할당 보장
$ cat requests-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: requests-pod
spec:
containers:
- image: busybox
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: main
resources:
requests:
cpu: 200m
memory: 10Mi$ kubectl exec -it requests-pod top
Mem: 2401244K used, 1533844K free, 658916K shrd, 31724K buff, 1573116K cached
CPU: 20.1% usr 33.6% sys 0.0% nic 45.9% idle 0.1% io 0.0% irq 0.1% sirq
Load average: 0.49 0.46 0.35 2/689 11
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
1 0 root R 1316 0.0 0 50.1 dd if /dev/zero of /dev/null
7 0 root R 1324 0.0 0 0.0 top
[CPU 사용량이 50%인 이유]
실습 상의 dd 커맨드는 사용 가능한 최대 CPU를 사용하지만, 스레드 하나로 실행되므로 코어 한개만 사용가능. Minikube VM은 2개의 코어가 할당되므로 CPU 50% 소비로 확인 가능. spec을 통해 200m, 200밀리코어, 즉 0.2코어를 요청했지만 사용량에 제한은 별도로 없었기 때문에 500m 사용해도 제한이 없었음.
One of the really interesting ways of stress testing CPUs on your system is using dd command. By making it work with /dev/zero and /dev/null (which are not real devices in terms of disk I/O), you’re effectively getting dd to shift a whole lot of zero bytes between addresses in virtual memory – thus causing CPU (and possibly a bit of RAM) stress.
https://www.unixtutorial.org/stress-testing-cpu-with-dd-command/
리소스 요청이 스케줄링에 미치는 영향
- 일반론
- 리소스 요청으로 정해진 파드 필요 리소스 최소량을 기반으로 스케줄러가 스케줄링을 진행.
스케줄러는 파드의 리소스 요청 사항을 만족하는 충분한 리소스를 보유한 노드만을 고려.
- 리소스 요청으로 정해진 파드 필요 리소스 최소량을 기반으로 스케줄러가 스케줄링을 진행.
- 스케줄러의 특정 노드 내 파드 실행 가능 여부 결정 방법
- 스케줄러는 각 개별 리소스 사용량이 아닌, 노드 내 파드들의 리소스 요청량 합계만을 확인.
사용량이 아닌 요청량만을 확인하여, 기 배포된 파드에 대한 요청량을 보장.
- 스케줄러는 각 개별 리소스 사용량이 아닌, 노드 내 파드들의 리소스 요청량 합계만을 확인.
- 스케줄러가 파드 요청량을 기반으로 최적의 노드를 선택하는 방법
- 1. 파드에 맞지 않은 노드를 제거하기 위해 노드 목록 필터링
- 2. 우선순위 함수를 기반으로 남은 노드 우선순위를 지정
- 우선 순위 함수 1) LeastRequestedPriority
- 요청된 리소스가 낮은 노드, 할당되지 않은 리소스 양이 많은 노드를 선호
- 우선 순위 함수 2) MostRequestedPriority
- 요청된 리소스가 가장 많은 노드를 선호
- 이를 통해 파드 요청량을 제공하면서도 가장 적은 수의 노드를 사용하도록 보장.
노드별 비용 지불 체계에서 비용 효율적.
- 우선 순위 함수 1) LeastRequestedPriority
- 노드의 용량
- capacity : 노드의 총 리소스.
- allocatable : 파드가 사용 가능한 노드 내 리소스. 스케줄러가 결정 기준으로 삼는 정보.
$ kubectl describe nodes
Name: minikube
Roles: control-plane,master
(중략)
Capacity: // 노드의 전체 용량
cpu: 2
ephemeral-storage: 17784752Ki
hugepages-2Mi: 0
memory: 3935088Ki
pods: 110
Allocatable: // 파드에 할당 가능한 리소스
cpu: 2
ephemeral-storage: 17784752Ki
hugepages-2Mi: 0
memory: 3935088Ki
pods: 110
(중략)
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 1050m (52%) 0 (0%)
memory 270Mi (7%) 170Mi (4%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
(후략)kubelet이 API 서버에 게시한 노드 리소스 정보를 기반으로 스케줄러가 스케줄링을 진행한다.
$ cat requests-pod-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: requests-pod-2
spec:
containers:
- image: busybox
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: main
resources:
requests:
cpu: 800m
memory: 20Mi
$ kubectl create -f requests-pod-2.yaml
pod/requests-pod-2 created$ kubectl run requests-pod-3 --image=busybox --restart Never --requests='cpu=1,memory=20Mi' -- dd if=/dev/zero of=/dev/null
Flag --requests has been deprecated, has no effect and will be removed in the future.
pod/requests-pod-3 created
$ kubectl get po
NAME READY STATUS RESTARTS AGE
requests-pod 1/1 Running 0 68m
requests-pod-2 1/1 Running 0 4m33s
requests-pod-3 0/1 Pending 0 12s
$ kubectl describe po requests-pod-3
Name: requests-pod-3
Namespace: default
Priority: 0
Node: <none> // 파드와 연관된 노드가 없음
(중략)
Containers:
requests-pod-3:
Image: busybox
Port: <none>
Host Port: <none>
Args:
dd
if=/dev/zero
of=/dev/null
Requests: // Has No Effect라 했지만 반영됨을 확인했다
cpu: 1
memory: 20Mi
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-w5f9v (ro)
Conditions:
Type Status
PodScheduled False // 파드가 스케줄링되지 않음
(중략)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 21s (x2 over 99s) default-scheduler 0/1 nodes are available: 1 Insufficient cpu.$ kubectl describe node
Name: minikube
(중략)
Non-terminated Pods: (14 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
bar test 0 (0%) 0 (0%) 0 (0%) 0 (0%) 4d22h
default requests-pod 200m (10%) 0 (0%) 10Mi (0%) 0 (0%) 91m
default requests-pod-2 800m (40%) 0 (0%) 20Mi (0%) 0 (0%) 27m
foo test 0 (0%) 0 (0%) 0 (0%) 0 (0%) 4d22h
ingress-nginx ingress-nginx-controller-6d5f55986b-4rk69 100m (5%) 0 (0%) 90Mi (2%) 0 (0%) 33d
kube-system coredns-64897985d-w9lm5 100m (5%) 0 (0%) 70Mi (1%) 170Mi (4%) 55d
kube-system etcd-minikube 100m (5%) 0 (0%) 100Mi (2%) 0 (0%) 55d
kube-system kube-apiserver-minikube 250m (12%) 0 (0%) 0 (0%) 0 (0%) 3d19h
kube-system kube-controller-manager-minikube 200m (10%) 0 (0%) 0 (0%) 0 (0%) 55d
kube-system kube-proxy-gqm9x 0 (0%) 0 (0%) 0 (0%) 0 (0%) 55d
kube-system kube-scheduler-minikube 100m (5%) 0 (0%) 0 (0%) 0 (0%) 55d
kube-system storage-provisioner 0 (0%) 0 (0%) 0 (0%) 0 (0%) 55d
kubernetes-dashboard dashboard-metrics-scraper-58549894f-5s4br 0 (0%) 0 (0%) 0 (0%) 0 (0%) 44d
kubernetes-dashboard kubernetes-dashboard-ccd587f44-s52d5 0 (0%) 0 (0%) 0 (0%) 0 (0%) 44d
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 1850m (92%) 0 (0%)
memory 290Mi (7%) 170Mi (4%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events: <none>
$ kubectl delete po requests-pod
pod "requests-pod" deleted
$ kubectl get po
NAME READY STATUS RESTARTS AGE
requests-pod-2 1/1 Running 0 40m
requests-pod-3 0/1 Pending 0 36m
$ kubectl delete po requests-pod-2
pod "requests-pod-2" deleted
$ kubectl get po
NAME READY STATUS RESTARTS AGE
requests-pod-3 0/1 ContainerCreating 0 36m
$ kubectl get po
NAME READY STATUS RESTARTS AGE
requests-pod-3 1/1 Running 0 37m[실습에서 3번째 파드가 스케줄링되지 않은 이유와 해결방법]
requests-pod, requests-pod-2는 각각 200밀리코어, 800밀리코어를 요청했으나, 결과적으로 하단의 총 CPU Requests는 1850밀리코어. 그 이유는 kube-system 네임스페이스 파드들이 CPU 리소스를 요청했기 때문.
파드는 적정 CPU 리소스 양이 남아 있는 경우 스케줄링되므로, 기존 파드를 삭제하면 스케줄러는 삭제를 통지받고 세번째 파드를 다시 스케줄링함을 확인했다.
CPU 요청이 CPU 시간 공유에 미치는 영향

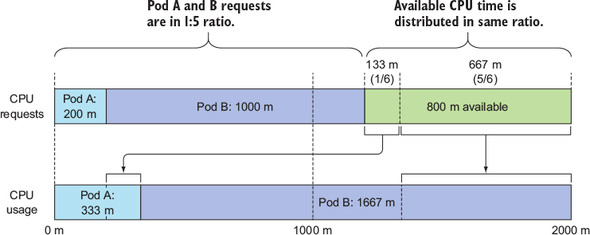
- 파드별 CPU 요청량에 비례하여 미사용 CPU시간을 파드 간에 분배
- 만약 특정 파드가 유휴 상태라면 해당 파드는 배분 과정에서 제외하고 다른 파드들이 전체를 기준으로 분배
사용자 정의 리소스 정의 및 요청
- 명칭
- 현재 Extended Resources (K8S v1.8 기준)
노드에 대한 확장 리소스를 통해 클러스터 관리자는 쿠버네티스에게 알려지지 않은 노드-레벨 리소스를 알릴 수 있다. https://kubernetes.io/ko/docs/tasks/administer-cluster/extended-resource-node/ - 과거 Opaque Integer Resources
- 현재 Extended Resources (K8S v1.8 기준)
- 활용법
- 1. 노드 오브젝트의 capacity 필드에 값을 추가해 사용자 정의 리소스를 쿠버네티스가 인식
(PATCH HTTP request 통해 수행)- EX) 노드에서 새로운 확장 리소스를 알리려면, 쿠버네티스 API 서버에 HTTP PATCH 요청을 보낸다. 예를 들어, 노드 중 하나에 4개의 동글(dongle)이 있다고 가정한다. 다음은 노드에 4개의 동글 리소스를 알리는 PATCH 요청의 예이다. https://kubernetes.io/ko/docs/tasks/administer-cluster/extended-resource-node/
- curl --header "Content-Type: application/json-patch+json" \
--request PATCH \
--data '[{"op": "add", "path": "/status/capacity/example.com~1dongle", "value": "4"}]' \ http://localhost:8001/api/v1/nodes/<your-node-name>/status - 리소스 이름은 kubernetes.io 도메인으로 시작하지 않는 임의의 이름
- 수량 값은 반드시 정수로 설정
- 2. capacity 필드에서 allocatable 필드로 자동으로 복사
- 3. 파드 생성 시 동일 리소스 이름 및 수량을 컨테이너 스펙 resources.requests 필드로 지정
- 책에서 추가적으로 서술한 kubectl run --requests의 경우 deprecated
- To request an extended resource, include the resources:requests field in your Container manifest. Extended resources are fully qualified with any domain outside of *.kubernetes.io/. Valid extended resource names have the form example.com/foo where example.com is replaced with your organization's domain and foo is a descriptive resource name.
https://kubernetes.io/docs/tasks/configure-pod-container/extended-resource/ - apiVersion: v1
kind:Pod
metadata:
name: extended-resource-demo
spec:
containers:
- name: extended-resource-demo-ctr
image: nginx
resources:
requests:
example.com/dongle: 3
limits:
example.com/dongle: 3
- 4. 스케줄러가 사용자 정의 리소스 사용 가능 노드에만 파드를 배포
- 1. 노드 오브젝트의 capacity 필드에 값을 추가해 사용자 정의 리소스를 쿠버네티스가 인식
- 사용자 정의 리소스, 확장 리소스 예시
- 노드에 사용 가능한 GPU 단위 수
컨테이너에 사용 가능한 리소스 제한
컨테이너가 사용 가능한 리소스 양을 엄격한 제한으로 설정
- 컨테이너에 할당되는 메모리의 최대량을 제한해야 하는 이유
- 메모리는 CPU와 달리 압축이 불가능하여, 컨테이너가 사용하는 메모리 양을 조절 시 프로세스에 부정적인 영향을 줄 수 있기 때문. 프로세스에 메모리가 주어지면 메모리 해제 이전까지 가져갈 수 없음.
- 메모리를 제한하지 않으면 실행 중인 컨테이너가 사용 가능한 모든 메모리를 사용하기 때문에 새로이 스케줄링되는 다른 신규 파드가 영향을 받아 전체 노드가 사용 불능 상태에 빠질 우려가 있음.
- 리소스 제한을 갖는 파드 생성
- spec.containers.resources.limits: cpu: 1 \ memory: 20Mi
cat limited-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: limited-pod
spec:
containers:
- image: busybox
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: main
resources:
limits:
cpu: 1
memory: 20Mi- 리소스 제한 오버커밋
- 리소스 제한은 노드의 할당 가능 리소스 양으로 제한되지 않음
- 노드 전체 파드 리소스 제한 합계 > 노드 용량 100%. 즉 리소스 제한은 오버커밋 가능.
- 노드 리소스 소진 시 특정 컨테이너 제거. 개별 컨테이너가 지정 제한 초과 시 종료 가능.
[CPU와 메모리의 차이]
* CPU는 압축 가능한 리소스. 프로세스가 I/O 동작을 대기하는 것이 아닌 경우 모든 CPU 시간을 사용한다. 프로세스의 CPU 사용률을 조절할 수 있기 때문에, 컨테이너에 CPU 제한이 있다면 설정된 제한보다 많은 시간을 할당받지 못한다.
* 메모리는 압축 불가능한 리소스. 프로세스가 제한보다 많은 메모리를 할당받으려 시도하면 프로세스가 OOM Killer에 의해 종료된다. (파드 재시작 정책이 Always 혹은 OnFailure일 경우 즉시 재시작한다. 메모리 제한 초과 및 종료가 지속되면 재시작 지연시간이 증가되면서 CrashLoopBackOff 상태로 표시된다.)
* CrashLoopBackOff 상태 : 크래시 후 kubelet이 컨테이너 재시작 전 지연 간격을 증가시키는 중.즉시 재시작 > 10초 > 20초 > 40초 > 80초 > 160초 > 300초로 증가 후 300초 제한 도달 시 크래시 종료 혹은 삭제 전까지 300초 간격 컨테이너 재시작.
* OOMKilled : 컨테이너 메모리 제한 초과, 메모리 부족으로 OOM Killer에 의해 종료. (컨테이너 제한 초과 사유가 아니더라도 OOM Killed 가능)
[압축 가능한 리소스에 대한 부연 설명]
* Quality-of-Service for Memory Resources
spec.containers[].resources.limits is passed to the container runtime when the kubelet starts a container. CPU is considered a "compressible" resource. If your app starts hitting your CPU limits, Kubernetes starts throttling your container, giving your app potentially worse performance. However, it won’t be terminated. That is what "compressible" means.
In cgroup v1, and prior to this feature, the container runtime never took into account and effectively ignored spec.containers[].resources.requests["memory"]. This is unlike CPU, in which the container runtime consider both requests and limits. Furthermore, memory actually can't be compressed in cgroup v1. Because there is no way to throttle memory usage, if a container goes past its memory limit it will be terminated by the kernel with an OOM (Out of Memory) kill.
https://kubernetes.io/blog/2021/11/26/qos-memory-resources/
* 압축 가능한 리소스인 CPU의 오버커밋 때문에 포드 간의 리소스 경합이 발생할 경우, 포드 내부의 프로세스의 CPU 사이클에 쓰로틀이 발생할 뿐 애플리케이션에 큰 문제가 발생하지는 않는다. 하지만 압축 불가능한 리소스인 메모리나 스토리지의 경우에는 이야기가 좀 다른데, 말 그대로 압축이 불가능하기 때문에 Out of Resource에 직면할 경우 뭔가 특별한 조치를 취해야만 한다. 메모리의 오버커밋으로 인한 자원 경합이 발생할 경우 포드 내부의 프로세스에 OOM (Out of Memory) 가 발생할 수도 있고, 로컬 스토리지가 부족하다면 사용 중이지 않은 도커 이미지나 포드 (컨테이너) 를 kubelet이 자동으로 삭제하기도 한다.
https://m.blog.naver.com/alice_k106/221676471427
* What is CPU throttling?
CPU throttling is also know as dynamic clock or dynamic frequency scaling. The basic idea is kind of like the throttle in your car, thus the “CPU throttling” name. When there’s a small load on your CPU, running it at a lower speed keeps it cooler and uses less power, especially when combined with voltage throttling. That’s because power use in a CPU is linear with clock frequency and superlinear with voltage. Particulalry on a mobile device, CPU throttling is what gets you a long runtime if you’re not spending all your time running the most demanding software.
https://www.quora.com/What-is-CPU-throttling
Adjusting the clock speed of the CPU. Also called "dynamic frequency scaling," CPU throttling is commonly used to automatically slow down the computer when possible to use less energy and conserve battery, especially in laptops. CPU throttling can also be adjusted manually to make the system quieter, because the fan can then run slower. Contrast with overclock. See thermal throttling.
https://www.pcmag.com/encyclopedia/term/cpu-throttling
- 컨테이너의 애플리케이션이 제한을 바라보는 방법
- 컨테이너는 컨테이너 메모리가 아닌 노드 메모리를 본다
- top 명령은 컨테이너 실행 중인 전체 노드의 메모리 양을 표시
- 컨테이너가 사용 가능 메모리를 제한해도 컨테이너는 이를 인식하지 못함
- 시스템 내 사용 가능 메모리 양 조회 후 해당 정보 기반 예약 메모리 양을 결정하는 애플리케이션에 부적합
- 자바 애플리케이션 실행 시 -Xms 옵션으로 JVM 최대 힙 크기를 지정하지 않은 경우 :
과거 버전 JVM은 컨테이너에 사용 가능한 메모리 대신 호스트 총 메모리 기준으로 최대 힙 크기 설정.
많은 물리 메모리를 갖는 프로덕션 환경에서 파드 배포 시 JVM이 컨테이너 메모리 제한을 초과해 OOM Killed 가능.
[JVM 1.8.192 이상은 JVM이 컨테이너 메모리 기준으로 최대 힙 크기를 설정하고, -XX:+UseCGroupMemoryLimitForHeap 옵션으로 cgroup 할당 컨테이너 메모리를 사용할 수 있음 ]
- 자바 애플리케이션 실행 시 -Xms 옵션으로 JVM 최대 힙 크기를 지정하지 않은 경우 :
- 컨테이너는 노드의 모든 CPU 코어를 본다
- 컨테이너는 CPU 제한과 무관히 노드 내 모든 CPU를 본다.
- CPU 제한 = 컨테이너가 사용할 수 있는 CPU 시간의 양의 제한.
CPU 제한 != 해당 양만큼만 컨테이너에 코어를 노출
CPU 제한이 1코어로 설정되어도 컨테이너 프로세스는 1개 코어에서만 실행되는 것이 아님. 다른 코어에서도 실행 가능. - 애플리케이션이 시스템 CPU 수를 검색해 실행할 작업 스레드 수를 결정하는 경우에 부적합
- 많은 수의 코어를 갖는 노드에 배포하면 너무 많은 스레드가 기동돼 제한된 CPU 시간을 두고 모두 경합
- 각 스레드별 추가적인 메모리가 요구돼 메모리 사용량 급증
- 해결책 :
- 시스템 내 확인 가능한 CPU 수에 의존하기보다 downwardAPI를 통해 컨테이너 CPU 제한을 확인
- 혹은 /sys/fs/cgroup/cpu.cfs_quota_us, /sys/fs/cgroup/cpu.cfs_period_us 등의 파일을 읽어 cgroup 내 직접 설정된 CPU 제한을 확인
- 컨테이너는 컨테이너 메모리가 아닌 노드 메모리를 본다
$ cat limited-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: limited-pod
spec:
containers:
- image: busybox
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: main
resources:
limits:
cpu: 1
memory: 20Mi
$ kubectl create -f limited-pod.yaml
$ kubectl exec -it limited-pod top
Mem: 2463212K used, 1471876K free, 658932K shrd, 64608K buff, 1589524K cached
CPU: 19.9% usr 33.7% sys 0.0% nic 46.1% idle 0.0% io 0.0% irq 0.1% sirq
Load average: 0.54 0.33 0.27 2/706 13
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
1 0 root R 1316 0.0 1 50.2 dd if /dev/zero of /dev/null
7 0 root R 1324 0.0 1 0.0 top
파드 QoS, Quality of Service 클래스
QoS 클래스 정의와 분류
쿠버네티스는 서비스 품질, Quality of Service라는 클래스를 통해 리소스 오버커밋이 발생할 때 어떤 파드를 종료시키고 어떤 파드에게 리소스를 할당할 지 파드별 우선순위를 지정한다.
- 파드의 QoS 클래스 정의
- 매니페스트의 별도 필드가 아닌, 파드 컨테이너 리소스 요청과 제한의 조합을 통해 파생
- 파드의 3가지 서비스 품질 클래스 분류
- BestEffort, 최하위 우선순위
- 아무런 리소스 요청과 제한이 없는 파드에 할당되는 클래스
- 최악의 경우 CPU 시간을 할당받지 못하며, 메모리 해제가 필요할 시 최우선으로 종료된다
- 설정된 메모리 제한도 없으므로 메모리가 충분하면 원하는만큼 메모리를 사용
- Burstable
- 경우 1 : 컨테이너의 리소스 제한이 요청과 일치하지 않는 단일 컨테이너 파드
- 경우 2 : 컨테이너 하나의 리소스 요청과 제한이 일치하지만, 다른 컨테이너는 지정하지 않은 경우
- 요청한 양만큼의 리소스를 확보하고, 필요 시 제한량 이하까지 추가 리소스 사용 가능
- Guaranteed, 최상위 우선순위
- 모든 컨테이너가 리소스 요청 = 리소스 제한인 파드, 동일한 파드에 할당
- 구체적인 조건 1 : CPU와 메모리에 리소스 요청, 제한이 모두 설정
- 구체적인 조건 2 : 각 컨테이너에 설정
- 구체적인 조건 3 : 리소스 요청과 제한이 동일 (각 컨테이너별로 모두 만족)
- 요청된 리소스의 양을 얻으나 추가 리소스 사용 불가
- 모든 컨테이너가 리소스 요청 = 리소스 제한인 파드, 동일한 파드에 할당
- 요청 혹은 제한이 명시되지 않은 경우
- 리소스 요청만 있고 제한을 지정하지 않은 경우는 요청 < 제한 케이스와 같이 취급함
- 리소스 요청이 명시적으로 설정되지 않은 경우 제한과 동일하게 설정되어 요청 = 제한 케이스임.
- BestEffort, 최하위 우선순위
- 다중 컨테이너 파드의 QoS 클래스
- 모든 컨테이너가 동일한 QoS인 경우 컨테이너 QoS = 파드 QoS
- 적어도 한 컨테이너가 다르면, 컨테이너 QoS와 무관히 파드 QoS = Burstable
- kubectl describe pod, 혹은 매니페스트 내 status.qosClass로 확인 가능
메모리가 부족할 때의 프로세스 종료 방법
- 일반적인 종료 순서
- BestEffort 클래스 최우선 종료 → Burstable 클래스 파드 종료 → Guaranteed 파드 종료
- Guaranteed 파드는 시스템 프로세스가 메모리를 필요로 하는 경우에만 종료
- 동일 QoS 클래스를 갖는 컨테이너의 경우
- 각 프로세스의 OOM 점수, OutOfMemory Score에 따라 높은 점수의 프로세스를 우선으로 선정해 종료.
- OOM 점수의 계산 기준
- 기준 1 : 프로세스가 소비하는 가용 메모리의 비율
- 기준 2 : 컨테이너의 요청된 메모리와 파드의 QoS 클래스를 기반으로 한 고정된 OOM 점수 조정
[공식 문서 상의 “고정된 OOM 점수 조정값” 설명]
kubelet의 메모리 회수가 가능하기 이전에 노드에 메모리 부족(out of memory, 이하 OOM) 이벤트가 발생하면, 노드는 oom_killer에 의존한다. kubelet은 각 파드에 설정된 QoS를 기반으로 각 컨테이너에 oom_score_adj 값을 설정한다.
Guaranteed QoS oom_score_adj = -997
BestEffort QoS oom_score_adj = 1000
Burstable QoS oom_score_adj = min(max(2, 1000 - (1000 * memoryRequestBytes) / machineMemoryCapacityBytes), 999)
참고: 또한, kubelet은 system-node-critical 파드 우선 순위(Priority)를 갖는 파드의 컨테이너에 oom_score_adj 값을 -997로 설정한다.
노드가 OOM을 겪기 전에 kubelet이 메모리를 회수하지 못하면, oom_killer가 노드의 메모리 사용률 백분율을 이용하여 oom_score를 계산하고, 각 컨테이너의 실질 oom_score를 구하기 위해 oom_score_adj를 더한다. 그 뒤 oom_score가 가장 높은 컨테이너부터 종료시킨다. 이는 곧, 스케줄링 요청에 비해 많은 양의 메모리를 사용하면서 QoS가 낮은 파드에 속한 컨테이너가 먼저 종료됨을 의미한다. 파드 축출과 달리, 컨테이너가 OOM으로 인해 종료되면, kubelet이 컨테이너의 RestartPolicy를 기반으로 컨테이너를 다시 실행할 수 있다.
출처 : https://kubernetes.io/ko/docs/concepts/scheduling-eviction/node-pressure-eviction/
네임스페이스별 파드에 대한 기본 요청과 제한 설정
LimitRange 리소스
- LimitRange 리소스 용도
- 컨테이너의 각 리소스에 (각 네임스페이스별) 최소, 최대 제한을 지정
LimitRange 범위에서 벗어난 매니페스트를 지닌 파드는 검증에 실패하여 거부된다.- 관리자가 네임스페이스마다 파드의 기본 / 최소 / 최대 리소스를 설정하는 데에 사용.
- 네임스페이스가 다른 팀을 분리하거나,
동일 클러스터 내 실행하는 개발/QA/스테이징/프로덕션 파드를 분리하는 경우,
각 네임스페이스에 다른 LimitRange를 사용해 네임스페이스별로 파드 크기를 조정할 수 있음.
- 리소스 요청을 명시적으로 지정하지 않은 컨테이너의 기본 리소스 요청을 지정
- 각 개별 파드, 컨테이너 혹은 LimitRange 오브젝트와 동일 네임스페이스에 생성되는 다른 유형의 오브젝트에 리소스 제한을 적용. 네임스페이스 내 모든 파드 가용 리소스 총량은 제한하지 않음.
- 즉, LimitRange 제한은 각 개별 파드/컨테이너에만 적용되므로 파드 수가 많아 클러스터 가용 리소스가 고갈되면 LimitRange로 보호되지 않음. ResourceQuota로 해결해야 함.
- 클러스터의 노드보다 큰 파드를 생성하려는 사용자를 저지.
- 컨테이너의 각 리소스에 (각 네임스페이스별) 최소, 최대 제한을 지정
- LimitRange 사용방식
- LimitRanger 어드미션 컨트롤 플러그인에서 사용됨
- 파드 매니페스트가 API 서버에 게시되면 LimitRanger 플러그인이 파드 스펙을 검증.
검증 실패시 매니페스트 거부.
$ cat limits.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: example
spec:
limits:
- type: Pod // 파드 전체에 리소스 제한을 지정
min: // 모든 파드의 컨테이너가 전체적으로 요청 가능한 최소 CPU, 메모리
cpu: 50m
memory: 5Mi
max: // 모든 파드의 컨테이너가 요청 및 제한하는 최대 CPU, 메모리
cpu: 1
memory: 1Gi
- type: Container // 컨테이너 제한은 해당 줄 아래에 지정
defaultRequest: // 명시적으로 요청 지정 없는 컨테이너 기본 요청값
cpu: 100m
memory: 10Mi
default: // 명시적으로 제한 지정 없는 컨테이너 기본 제한값
cpu: 200m
memory: 100Mi
min: // 컨테이너가 가질 수 있는 최소 요청/제한
cpu: 50m
memory: 5Mi
max: // 컨테이너가 가질 수 있는 최대 요청/제한
cpu: 1
memory: 1Gi
maxLimitRequestRatio: // 각 리소스의 제한과 요청 간의 최대 비율
cpu: 4 // CPU는 제한이 요청보다 4배 이상 큰값이 될 수 없음
memory: 10
- type: PersistentVolumeClaim // PVC가 요청할 수 있는 스토리지 최소/최대량 설정
min:
storage: 1Gi
max:
storage: 10Gi- LimitRange 생성 방법 및 실제 명세 확인
- yaml 파일 기반 생성
- 유형에 따라 LimitRange 오브젝트를 여러개로 분할해서 생성, 관리할 수도 있음.
여러 오브젝트의 제한은 파드 및 PVC 검증 과정에서 통합되어 사용됨.
실습 (강제 리소스 제한 확인, 기본 리소스 요청 및 제한 적용)
$ kubectl create -f limits.yaml
limitrange/example created
$ cat limits-pod-too-big.yaml
apiVersion: v1
kind: Pod
metadata:
name: too-big
spec:
containers:
- image: busybox
args: ["sleep", "9999999"]
name: main
resources:
requests:
cpu: 2 // LimitRange에서 지정한 최대값보다 큰 요청값을 지닌 파드
$ kubectl create -f limits-pod-too-big.yaml
The Pod "too-big" is invalid: spec.containers[0].resources.requests: Invalid value: "2": must be less than or equal to cpu limit
$ kubectl create -f ../Chapter03/kubia-manual.yaml
pod/kubia-manual created
$ kubectl describe po kubia-manual
(중략)
Containers:
kubia:
(중략)
Limits: // 컨테이너의 요청과 제한이 LimitRange 오브젝트에서 지정한 것과 일치
cpu: 200m
memory: 100Mi
Requests:
cpu: 100m
memory: 10Mi
(후략)
네임스페이스 사용 가능 총 리소스 제한
리소스쿼터 오브젝트 소개
- 리소스쿼터 오브젝트 용도
- 클러스터 관리자가 네임스페이스 내 사용 가능 총 리소스를 제한
- 네임스페이스에서 파드가 사용가능한 컴퓨팅 리소스 양, 퍼시스턴트볼륨클레임 사용 가능 스토리지 양 제한
- 네임스페이스 내 사용자가 생성 가능한 파드, 클레임, 기타 API 오브젝트 수를 제한
- 리소스쿼터 작동 방식
- 리소스쿼터 어드미션 컨트롤 플러그인이 생성 중인 파드가 리소스쿼터 초과 여부를 확인
- 초과 시 파드 생성이 거부됨.
- 리소스쿼터 생성
- yaml 파일 기반 생성
- $ cat quota-cpu-memory.yaml apiVersion: v1 kind: ResourceQuota metadata: name: cpu-and-mem spec: hard: requests.cpu: 400m requests.memory: 200Mi limits.cpu: 600m limits.memory: 500Mi
- 리소스쿼터 이용 시 유의점
- 파드 생성시에만 적용되므로 리소스쿼터 오브젝트 생성 후 신규 파드에만 적용. 소급되지 않음.
- 오브젝트가 생성된 네임스페이스에 적용되지만, 개별 파드 / 컨테이너 수준 적용이 아닌, 모든 파드의 리소스 요청 및 제한의 총합에 적용.
- 리소스쿼터 생성 시 LimitRange 오브젝트도 함께 생성해야 함.
LimitRange 없이 리소스쿼터만 있을 경우 개별 파드 생성 시 리소스쿼터의 정의 항목과 동일한 리소스에 대한 요청 또는 제한이 각각 설정되지 않으면 파드가 거부되기 때문. 리소스 기본값을 채워주는 LimitRange를 미리 준비해 파드 생성을 용이하게 해야.
- 퍼시스턴트 스토리지 리소스쿼터 지정
- 네임스페이스에 요청할 수 있는 퍼시스턴트 스토리지 양을 제한
$ cat quota-storage.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: storage
spec:
hard:
// 요청 가능한 스토리지 전체 용량 (모든 퍼시스턴트 볼륨 클레임 요청가능 제한량)
requests.storage: 500Gi
// ssd 스토리지 클래스에서 요청 가능한 스토리지 용량
// 퍼시스턴트볼륨클레임은 특정 스토리지 클래스에 동적프로비저닝 PV 요청 가능하므로
// 쿠버네티스가 각 스토리지 클래스별로 스토리지 쿼터 정의
ssd.storageclass.storage.k8s.io/requests.storage: 300Gi
// standard 스토리지 클래스는 HDD 스토리지 클래스를 의미
standard.storageclass.storage.k8s.io/requests.storage: 1Ti
- 생성 가능한 오브젝트 수 제한
- 네임스페이스 내 파드, 레플리케이션컨트롤러, 서비스 등 오브젝트 수 제한 구성
- 클러스터 관리자는 사용자의 결제 플랜 따라 생성 오브젝트 수 제한 가능
- 서비스가 사용 가능한 퍼블릭 IP 또는 노드포트 수를 제한
- 수 제한 설정 가능한 오브젝트 종류 : 이전에는 레플리카셋, 잡, 디플로이먼트, 인그레스 등이 제한되지 못했으나 이제는 표준 네임스페이스 처리된 전체 리소스 유형에 대해 쿼터 설정이 가능.
- 파드, 레플리케이션컨트롤러, 시크릿, 컨피그맵, 퍼시스턴트볼륨클레임
- 서비스, 로드밸런서, 노드포트 등 2가지 유형 서비스
- 리소스쿼터 오브젝트 자체의 수 쿼터
- [최신 정보] 다음 구문을 사용하여 모든 표준 네임스페이스 처리된(namespaced) 리소스 유형에 대한 특정 리소스 전체 수에 대하여 쿼터를 지정할 수 있다. ( 출처 : https://kubernetes.io/ko/docs/concepts/policy/resource-quotas/ )
- 코어 그룹이 아닌(non-core) 리소스를 위한 count/<resource>.<group>
- 코어 그룹의 리소스를 위한 count/<resource>
$ cat quota-object-count.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: objects
spec:
hard:
// 네임스페이스 내 리소스 수 제한
pods: 10
replicationcontrollers: 5
secrets: 10
configmaps: 10
persistentvolumeclaims: 5
// 네임스페이스 내 서비스 수 제한 (종류별 제한 포함)
services: 5
services.loadbalancers: 1
services.nodeports: 2
// ssd 스토리지 클래스 이용 2개의 PVC가 스토리지 요청 가능 (스토리지클래스별 지정 가능)
ssd.storageclass.storage.k8s.io/persistentvolumeclaims: 2
- 특정 파드 상태나 QoS 클래스 쿼터 지정
- 쿼터 범위를 제한해 리소스쿼터를 지정.
- 사용 가능 범위 : BestEffort, NotBestEffort, Terminating, NotTerminating
- BestEffort, NotBestEffort : 쿼터가 BestEffort QoS 클래스인지 아닌지에 따라 결정
- Terminating, NotTerminating : 종료 이전 혹은 종료 과정 중의 파드에 적용되지 않음.
- 종료 이후 실패 표시 전 실행 기간을 지정하는, 파드 스펙의 activeDeadlineSeconds 필드를 설정하면, 파드가 실패로 표시된 후 종료 전, 시작 시간 기준 노드 내 활성화 허용 시간을 정의.
- Terminating = activeDeadlineSeconds 필드 설정된 파드
- NotTerminating = activeDeadlineSeconds 필드 설정되지 않은 파드
- 사용 가능 범위 : BestEffort, NotBestEffort, Terminating, NotTerminating
- 리소스 쿼터 생성 시 적용 범위 지정 조건
- 쿼터 적용 시 파드가 지정 범위 모두와 일치해야 함
- 쿼터 제한은 쿼터 범위에 의존
- BestEffort 범위는 파드 수만 제한 가능
- NotBestEffort, Terminating, NotTerminating 범위는 파드 수, CPU / 메모리 요청 및 제한 설정 가능
- 쿼터 범위를 제한해 리소스쿼터를 지정.
$ cat quota-scoped.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: besteffort-notterminating-pods
spec:
scopes:
// BestEffort QoS를 갖고 activeDeadlineSeconds 필드가 설정되지 않은 파드에만 적용
- BestEffort
- NotTerminating
hard:
// 해당 범위 조건을 만족하는 파드는 4개로 제한
pods: 4
파드 리소스 사용량 모니터링
실제 리소스 사용량 수집 및 검색
- 리소스 사용량 모니터링 목적
- 리소스 요청과 제한의 적정 지점을 찾아야 하기 때문.
- 리소스 요청이 너무 높으면 클러스터 노드 활용도 감소로 비용 낭비
- 리소스 요청이 너무 낮으면 애플리케이션 리소스 부족 및 OOM killed 발생 가능
- 리소스 요청과 제한의 적정 지점을 찾아야 하기 때문.
- 리소스 사용 데이터 수집
- kubelet 자체에 cAdvisor 에이전트가 포함돼, 노드 내 실행 개별 컨테이너 및 노드 전체 리소스 사용 데이터 수집
- cAdvisor는 파드의 컨테이너 내부 프로세스와 통신하지 않음
- 리소스 사용 데이터 중앙 수합
힙스터라는 추가 구성 요소를 통해 전체 클러스터 통계를 중앙에서 수집힙스터 리소스 개요노드 중 하나의 파드로 실행일반 쿠버네티스 서비스로 노출돼 안정적인 IP 주소 제공클러스터 내 모든 cAdvisor에 연결하여 그로부터 데이터 수집해 하나로 노출힙스터에서 수집한 메트릭은 즉시 노출되지 않고 데이터 집계가 몇분 소요됨.
$ minikube addons enable heapster
⌛ using metrics-server addon, heapster is deprecated
▪ Using image k8s.gcr.io/metrics-server/metrics-server:v0.4.2
🌟 'metrics-server' 애드온이 활성화되었습니다
Heapster는 더이상 사용되지 않음
RETIRED: Heapster is now retired. See the deprecation timeline for more information on support. We will not be making changes to Heapster.
The following are potential migration paths for Heapster functionality:
- For basic CPU/memory HPA metrics: Use metrics-server.
- For general monitoring: Consider a third-party monitoring pipeline that can gather Prometheus-formatted metrics. The kubelet exposes all the metrics exported by Heapster in Prometheus format. One such monitoring pipeline can be set up using the Prometheus Operator, which deploys Prometheus itself for this purpose.
- For event transfer: Several third-party tools exist to transfer/archive Kubernetes events, depending on your sink. heptiolabs/eventrouter has been suggested as a general alternative.
https://github.com/kubernetes-retired/heapster
리소스 메트릭 파이프라인
리소스 메트릭 파이프라인은 Horizontal Pod Autoscaler 컨트롤러와 같은 클러스터 구성요소나 kubectl top 유틸리티에 관련되어 있는 메트릭들로 제한된 집합을 제공한다. 이 메트릭은 경량의 단기 인메모리 저장소인 metrics-server에 의해서 수집되며 metrics.k8s.io API를 통해 노출된다.
metrics-server는 클러스터 상의 모든 노드를 발견하고 각 노드의 Kubelet에 CPU와 메모리 사용량을 질의한다. Kubelet은 쿠버네티스 마스터와 노드 간의 다리 역할을 해서 머신에서 구동되는 파드와 컨테이너를 관리한다. Kubelet은 각각의 파드를 해당하는 컨테이너로 변환하고 컨테이너 런타임 인터페이스를 통해서 컨테이너 런타임에서 개별 컨테이너의 사용량 통계를 가져온다. Kubelet은 이 정보를 레거시 도커와의 통합을 위해 kubelet에 통합된 cAdvisor를 통해 가져온다. 그 다음으로 취합된 파드 리소스 사용량 통계를 metric-server 리소스 메트릭 API를 통해 노출한다. 이 API는 kubelet의 인증이 필요한 읽기 전용 포트 상의 /metrics/resource/v1beta1에서 제공된다.
https://kubernetes.io/ko/docs/tasks/debug-application-cluster/resource-usage-monitoring/
Metrics Server is a scalable, efficient source of container resource metrics for Kubernetes built-in autoscaling pipelines.
Metrics Server collects resource metrics from Kubelets and exposes them in Kubernetes apiserver through Metrics API for use by Horizontal Pod Autoscaler and Vertical Pod Autoscaler. Metrics API can also be accessed by kubectl top, making it easier to debug autoscaling pipelines.
Metrics Server is not meant for non-autoscaling purposes. For example, don't use it to forward metrics to monitoring solutions, or as a source of monitoring solution metrics. In such cases please collect metrics from Kubelet /metrics/resource endpoint directly.
Metrics Server offers:
- A single deployment that works on most clusters (see Requirements)
- Fast autoscaling, collecting metrics every 15 seconds.
- Resource efficiency, using 1 mili core of CPU and 2 MB of memory for each node in a cluster.
- Scalable support up to 5,000 node clusters.
https://github.com/kubernetes-sigs/metrics-server
- 클러스터 노드의 CPU 및 메모리 사용량 표시
- 클러스터 내 힙스터 실행 후 kubectl top 명령으로 사용량 확인
- 노드 내 실행 중인 모든 파드의 실제 CPU, 메모리 사용량 표시
- 그와 달리 kubectl describe node 명령은 런타임 사용량 데이터 대신 CPU 및 메모리 요청/제한량 표시
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
minikube 142m 7% 1569Mi 40%
- 개별 파드의 CPU와 메모리 사용량 표시
- kubectl top pod
$ kubectl top pod --all-namespaces
NAMESPACE NAME CPU(cores) MEMORY(bytes)
bar test 0m 8Mi
foo test 0m 9Mi
ingress-nginx ingress-nginx-controller-6d5f55986b-4rk69 0m 100Mi
kube-system coredns-64897985d-w9lm5 0m 12Mi
kube-system etcd-minikube 0m 66Mi
kube-system kube-apiserver-minikube 0m 228Mi
kube-system kube-controller-manager-minikube 0m 41Mi
kube-system kube-proxy-gqm9x 0m 16Mi
kube-system kube-scheduler-minikube 0m 14Mi
kube-system metrics-server-6b76bd68b6-ft8bv 0m 5Mi
kube-system storage-provisioner 0m 9Mi
kubernetes-dashboard dashboard-metrics-scraper-58549894f-5s4br 0m 4Mi
kubernetes-dashboard kubernetes-dashboard-ccd587f44-s52d5 0m 9Mi
기간별 리소스 사용량 통계 저장 및 분석
- 통계 확인 방법 1 : top 명령
- 현재 리소스 사용량만 표시. 과거 장기간 리소스 사용량 데이터 확인 불가.
- 통계 확인 방법 2 : GKE 구글 클라우드 모니터링
- 통계 확인 방법 3 : 인플럭스DB (로컬 쿠버네티스 클러스터 실행용)
- 애플리케이션 메트릭 및 모니터링 데이터를 저장하는 오픈소스 시계열 데이터베이스
- 통계 확인 방법 4 : 그라파나 (시각화 및 분석용)
- 데이터베이스에 저장된 데이터를 시각화하고 리소스 사용량 변화 추이를 확인하는 웹콘솔 및 분석/시각화 제품
- heapster deprecated된 관계로 실습이 어려움 (힙스터와 함께 인플럭스, 그라파나 배포되던 것이 사라짐)
$ kubectl cluster-info
Kubernetes control plane is running at https://192.168.59.100:8443
CoreDNS is running at https://192.168.59.100:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
$ minikube service monitoring-grafana -n kube-system
❌ Exiting due to SVC_NOT_FOUND: Service 'monitoring-grafana' was not found in 'kube-system' namespace.
You may select another namespace by using 'minikube service monitoring-grafana -n <namespace>'. Or list out all the services using 'minikube service list'
대체 실습 (Prometheus + Grafana)
실습 기반 ) https://newbiecs.tistory.com/330
$ kubectl create namespace monitor
namespace/monitor created
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
"prometheus-community" has been added to your repositories
$ helm install prometheus prometheus-community/prometheus
NAME: prometheus
LAST DEPLOYED: Wed Mar 23 16:42:36 2022
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
The Prometheus server can be accessed via port 80 on the following DNS name from within your cluster:
prometheus-server.default.svc.cluster.local
Get the Prometheus server URL by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace default -l "app=prometheus,component=server" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace default port-forward $POD_NAME 9090
The Prometheus alertmanager can be accessed via port 80 on the following DNS name from within your cluster:
prometheus-alertmanager.default.svc.cluster.local
Get the Alertmanager URL by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace default -l "app=prometheus,component=alertmanager" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace default port-forward $POD_NAME 9093
#################################################################################
###### WARNING: Pod Security Policy has been moved to a global property. #####
###### use .Values.podSecurityPolicy.enabled with pod-based #####
###### annotations #####
###### (e.g. .Values.nodeExporter.podSecurityPolicy.annotations) #####
#################################################################################
The Prometheus PushGateway can be accessed via port 9091 on the following DNS name from within your cluster:
prometheus-pushgateway.default.svc.cluster.local
Get the PushGateway URL by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace default -l "app=prometheus,component=pushgateway" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace default port-forward $POD_NAME 9091
For more information on running Prometheus, visit:
https://prometheus.io/
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
prometheus-alertmanager-7b5bbc9d8d-276bt 0/2 ContainerCreating 0 12s
prometheus-kube-state-metrics-7cd8f95c7b-sblv2 1/1 Running 0 12s
prometheus-pushgateway-7966b84df6-mclvm 0/1 ContainerCreating 0 12s
prometheus-server-5448dffb5c-zg82j 0/2 ContainerCreating 0 12s
$ export POD_NAME=$(kubectl get pods --namespace default -l "app=prometheus,component=server" -o jsonpath="{.items[0].metadata.name}")
$ kubectl --namespace default port-forward $POD_NAME 9090
$ helm repo add grafana https://grafana.github.io/helm-charts
"grafana" has been added to your repositories
$ helm install grafana grafana/grafana
W0323 16:47:05.641636 75299 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W0323 16:47:05.643875 75299 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W0323 16:47:05.704318 75299 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W0323 16:47:05.706570 75299 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
NAME: grafana
LAST DEPLOYED: Wed Mar 23 16:47:05 2022
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
1. Get your 'admin' user password by running:
kubectl get secret --namespace default grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
2. The Grafana server can be accessed via port 80 on the following DNS name from within your cluster:
grafana.default.svc.cluster.local
Get the Grafana URL to visit by running these commands in the same shell:
export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=grafana" -o jsonpath="{.items[0].metadata.name}")
kubectl --namespace default port-forward $POD_NAME 3000
3. Login with the password from step 1 and the username: admin
#################################################################################
###### WARNING: Persistence is disabled!!! You will lose your data when #####
###### the Grafana pod is terminated. #####
#################################################################################
$ kubectl get secret --namespace default grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
(임의의 패스워드 값이 출력됨)
$ export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=grafana" -o jsonpath="{.items[0].metadata.name}")
$ kubectl --namespace default port-forward $POD_NAME 3000
error: unable to forward port because pod is not running. Current status=Pending$ kubectl edit psp grafana
Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
podsecuritypolicy.policy/grafana edited
$ kubectl get po
NAME READY STATUS RESTARTS AGE
grafana-5fd55596b5-hg6tn 0/1 Blocked 0 16m
$ kubectl get pod grafana-5fd55596b5-hg6tn -o yaml | kubectl replace --force -f-
pod "grafana-5fd55596b5-hg6tn" deleted
pod/grafana-5fd55596b5-hg6tn replaced
$ kubectl get po
NAME READY STATUS RESTARTS AGE
grafana-5fd55596b5-9pkm4 0/1 ContainerCreating 0 17s
$ export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=grafana,app.kubernetes.io/instance=grafana" -o jsonpath="{.items[0].metadata.name}")
$ kubectl --namespace default port-forward $POD_NAME 3000
Forwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
grafana 파드 설치 오류 해결 방법 :
PSP에서 apparmor 관련 어노테이션 삭제
https://www.ibm.com/docs/en/cloud-paks/cp-management/1.3.0?topic=issues-pods-fail-start-because-apparmor-disabled

$ helm delete prometheus
release "prometheus" uninstalled
$ helm delete grafana
W0323 17:41:12.063952 80090 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
W0323 17:41:12.063958 80090 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
release "grafana" uninstalled
실전 지식
- 모니터링의 경우, 현재 몸담고 있는 팀에서는 프로메테우스 - 그라파나 사이를 잇는 빅토리아메트릭스를 활용한다
- 빅토리아메트릭스는, 멀티 프로메테우스 환경의 구성을 돕는다
- 여러 클러스터들의 프로메테우스 데이터들을 빅토리아메트릭스로 수합하여 그라파나 대시보드로 확인한다
- https://victoriametrics.com/
- 리소스의 요청 및 제한량 설정에서의 핵심은 성능테스트이다
- 벤치마킹 툴을 활용해서 성능 테스트를 진행한뒤 테스트 정보를 기반으로 적정 제한량을 산정한다
- 성능 테스트의 내용은, 서비스 동시접속자 N명, 동시 트랜잭션 N건까지 소화 가능한지를 측정하는 것이다
- 비즈니스 상의 목표치를 설정하고, 그에 대한 부하를 인프라가 소화할 수 있는지 테스트해봐야 한다
- 만약 성능테스트가 어렵다면 배포 후 모니터링을 통해 성능 메트릭을 확인해 요청/제한량을 조절하는 것이 최선
- 과거에는 로드러너를 사용했다
- 현재 기준으로는 오픈소스 JMeter가 사용되는 것으로 추정된다
참고 자료
- 공식문서 [컨테이너 리소스 관리] https://kubernetes.io/ko/docs/concepts/configuration/manage-resources-containers/
- 공식문서 [컨테이너 및 파드 메모리 리소스 할당] https://kubernetes.io/ko/docs/tasks/configure-pod-container/assign-memory-resource/
- 공식문서 [Assign CPU Resources to Containers and Pods] https://kubernetes.io/docs/tasks/configure-pod-container/assign-cpu-resource/
- 공식문서 [kubectl run flags] https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands#run
- 공식문서 [노드에 대한 확장 리소스 알리기] https://kubernetes.io/ko/docs/tasks/administer-cluster/extended-resource-node/
- 공식문서 [Assign Extended Resources to a Container] https://kubernetes.io/docs/tasks/configure-pod-container/extended-resource/
- 공식문서 [노드-압박 축출] https://kubernetes.io/ko/docs/concepts/scheduling-eviction/node-pressure-eviction/
- 공식문서 [리소스 쿼터] https://kubernetes.io/ko/docs/concepts/policy/resource-quotas/
- 공식문서 [리소스 모니터링 도구] https://kubernetes.io/ko/docs/tasks/debug-application-cluster/resource-usage-monitoring/
- [kubernetes-retired / heapster] https://github.com/kubernetes-retired/heapster
- [kubernetes-sigs/metrics-server] https://github.com/kubernetes-sigs/metrics-server
- [Another OOM killer rewrite] https://lwn.net/Articles/391222/
- [Kubernetes Overview Diagrams] https://shipit.dev/posts/kubernetes-overview-diagrams.html
- [Chapter 14. Managing pods’ computational resources] https://livebook.manning.com/book/kubernetes-in-action/chapter-14/
- [Kuberntes - Monitoring에 대해 알아보자 (Prometheus, Grafana) [실습환경 minikube]] https://newbiecs.tistory.com/330
'기술 공부 > 쿠버네티스' 카테고리의 다른 글
| 쿠버네티스 (16) | 스케줄링 심화 (0) | 2022.03.31 |
|---|---|
| 쿠버네티스 (15) | 오토스케일링 (0) | 2022.03.31 |
| 쿠버네티스 (13) | 클러스터 노드와 네트워크 보안 (0) | 2022.03.23 |
| 쿠버네티스 (12) | API 서버 보안 (0) | 2022.03.20 |
| 쿠버네티스 (11) | 쿠버네티스 내부 이해 (0) | 2022.03.10 |